Individuals have not hit the limits of their potential. Groups of individuals are even farther from their potential. Step by step, we do the hard work to deliver working products that empower everyone to continuously dream bigger, even in the most complex scenarios. We let every individual dream bigger. We let every organization dream bigger. We dream bigger.
Today, we are releasing the next series of AI products that allow developers and organizations to dream bigger. Rapid large-scale multi-step reasoning to tackle more complex tasks, code review assistance to get changes into production quicker, and semantic encoding of organizational best practices to accelerate knowledge transfer. On our ongoing quest towards our mission to maximize human potential, we keep our track record of truly delivering the forefront of possibility today.
The Future of Codeium
Our goal at Codeium is to enable developers and organizations to do things that they could not do before Codeium.
We can do this both directly and indirectly, and so far, we directly write over 45% of committed code and indirectly unlock cycles to do more creative work. By accelerating developers through code generation via Autocomplete, code explanation/documentation via Chat, and code refactoring via Command, we have freed up brain cycles so that developers can spend more time on the creative parts of the job. This indirectly allows a developer to think and do things that they wouldn’t have otherwise. Similarly, with a state-of-the-art context awareness engine, we automatically help organizations share their best practices across their developers, saving undifferentiated cycles on maintaining coding standards and best practices. This also allows developers to onboard more quickly independently, freeing up time from senior developers spent on answering questions, allowing them to think and build the next great business-driving solution.
That being said, we have always believed we can do more than saving time on boilerplate. We want to empower developers and organizations to do things they would not be able to do without Codeium. In fact, we have always been working on new fundamental paradigms that allow developers to reason about large or difficult problems where AI assistance is a value creator, not just a value accelerator.
We believe we are at an inflection point where Codeium will start to directly enable developers and organizations to turn their bigger dreams into reality.
And as always, we will not simply be hyping up a vision of the future, we will be rolling out the actual technology to developers to use.
Riptide: A New Reasoning Engine
How can a tool help with the following tasks?
- A developer changes an API signature or adds a field to a schema, and now wants to change all call sites and queries to match the semantics of the new API signature or schema.
- A new security vulnerability is discovered, and a company wants to find all the other places in the code where something remotely similar is being done (and bonus points for proactively suggesting fixes).
- A framework version update has come to something such as Spring, and heuristic rules do not assist in human-required decision making, such as how to replace a deprecated class.
- A company has important business logic in an outdated language such as COBOL and wants to modernize the stack.
The current iteration of code assistants are what we classify as “single shot,” which means that, even with a very advanced context awareness system and complex pre-and-post processing logic, at the core there is a single LLM inference. All of these proposed tasks require larger reasoning or edits across multiple locations and files (or both). Yet, these are still not the creative tasks in a software engineer’s job, so saving time here will unlock time for developers to be more creative and solve bigger and better problems.
Introducing Riptide. A blazingly-fast state-of-the-art reasoning system that will be integrated into all of our products and surfaces.
How does it work? We break down a task similar to how a developer approaches any task - we first retrieve all of the snippets across the codebase that are relevant to the task at hand, then we semantically plan all of the steps we would need to take to solve the task, and then we go in and execute each of those steps. This abstraction applies no matter the task - writing code, refactoring code, reviewing code, explaining code, etc.
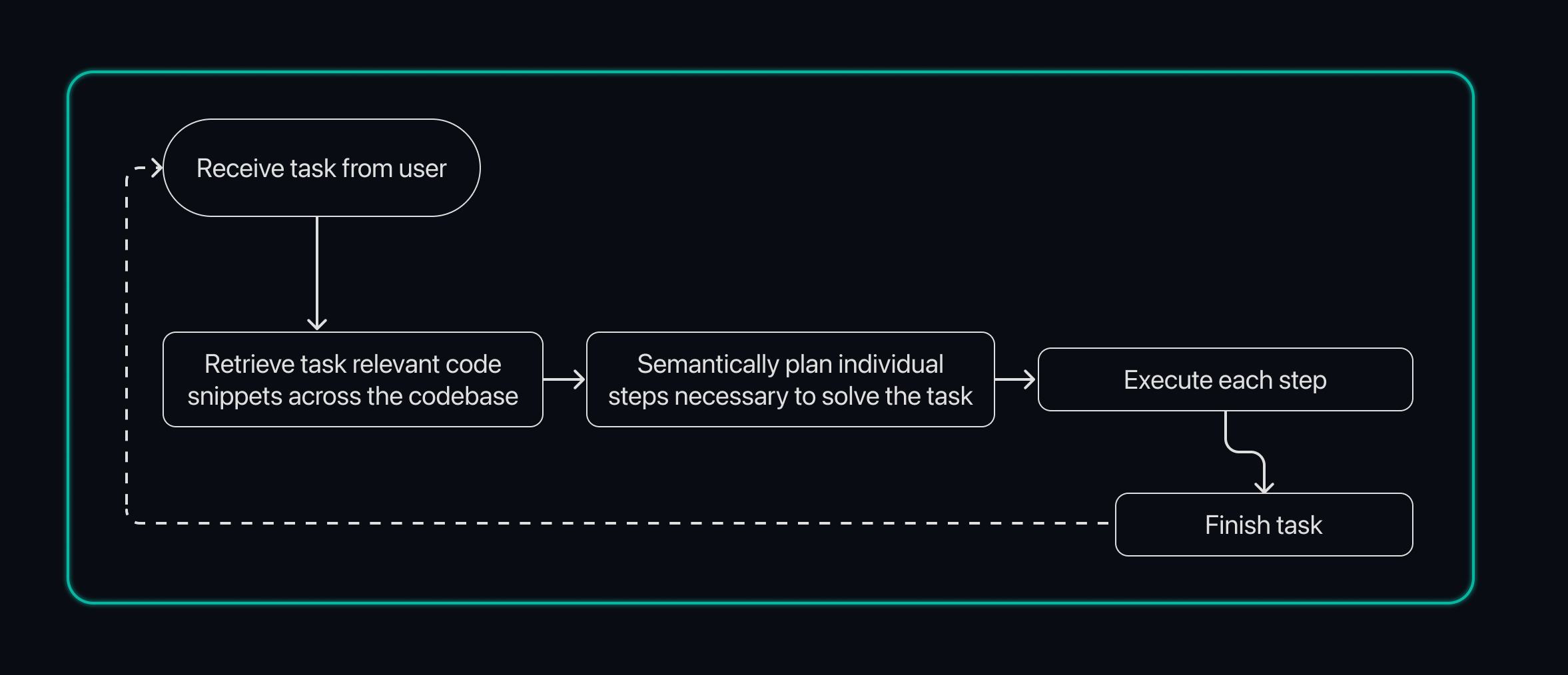
While conceptually clean, the devil is in the details of how we tactically achieved this with a series of breakthroughs.
Breakthrough #1: New Paradigm on Reasoning
We have built a proprietary foundational code LLM that can scale reasoning over variable amounts of context, tested on over 100M tokens of code with no degradation in quality.
In theory, reasoning over large corpuses of data is the one place where a tool should completely outclass a human. The ability to process crazy amounts of data is one of the core ways that any tool assists a human. However, today’s state-of-the-art reasoning systems for LLM applications are hampered by fixed maximum context lengths, forcing the use of embeddings via solutions like Retrieval Augmented Generation (RAG) on vector databases.
When you have to reason about the whole codebase, embedding vector-based retrieval simply starts to break down as the codebase gets larger. Let’s run some math. Suppose that there are 5 necessary “snippets” of context for a task, and your model can fit 20 snippets in its context length for RAG. Most personal project codebases have less than 10k lines of code, which is ~200 snippets. As long as your 5 snippets are in the top 10% of all snippets when scored on retrieval, the system works! But if you have a codebase of 1M lines of code (which is actually quite small), you’d have ~20k snippets. The retrieval system would have to guarantee your 5 snippets are in the top 0.1% when scored on retrieval. The required retrieval accuracy is orders of magnitude higher, which is why naive RAG is so magical when tested on dummy repositories but more disappointing when used in production.
At the end of the day, the embedding space has a fixed number of dimensions, so the more blocks there are that need to be parsed, the less distance there is on average between pairs of embedding vectors. When computing embeddings, you are making some approximation of the things that a retriever will eventually care about, and this is why there will always be “false positives,” i.e. snippets that the system thinks are useful context but are really unrelated and are just in the similar embedding space purely due to size-of-codebase reasons. The larger the number of reference vectors in a fixed query space, for any query embedding vector, there is a much higher chance of pulling in these false positives.
Since it is the first stage, retrieval is critical. If you retrieve more garbage, you generate worse results.
So what’s the magical insight to improve reasoning? Instead of relying on embeddings to help tell us what is relevant context (or trying to arbitrarily increase context lengths and model sizes hoping that that works), we have trained a proprietary foundational code LLM that can scale with variable amounts of context, powered by scaling the underlying compute layer. We have tested its capabilities on codebases of over 100M tokens of code, observing no degradation on retrieval or reasoning quality.
It is a bit of a crazy idea, with a vast cluster of GPUs spinning up for a couple of seconds just to give a single user significantly higher quality reasoning results, but across a lot of developers, we can still efficiently utilize the compute in aggregate. This is an unheard amount of compute power at a developer’s fingertips for a brief time, but it is the exact paradigm shift that can expand the reasoning potential of a system like Codeium.
The results speak for themselves. One way we know the reasoning is sound is by looking at retrieval recall. Retrieval recall is simply the fraction of the top N “most relevant” snippets (as determined by the reasoning system) that are known to be ground truth relevant to the query. One can create retrieval evaluation ground truth samples by using commit data to correlate intent (commit message) with relevant code snippets (edited snippets in the commit diff). Riptide has 3x the recall of state-of-the-art embedding systems.
Breakthrough #2: Latency that Makes Sense
High quality still doesn’t mean perfect. If AI is always going to make mistakes on an unknown and changing set of tasks, the way to still give value to a developer on the successful tasks is to get results quickly. Failing fast is okay, failing slow is not.
There have been a lot of demo videos and announcements of AI tools that promise being able to solve tasks end-to-end or help assist in these higher level reasoning tasks.
However, every demo that has been shown has centered around the “accuracy” of the results, that they can solve certain complex problems well. Yet, a major cause for concern that we have heard from developers and companies is the latency - sometimes hours to complete small tasks. If you have such a slow system, you can not afford to be even slightly incorrect even a small fraction of the time because a developer would simply lose trust. That is a very high bar, and with simpler workloads like autocomplete still having its imperfections, it is naive to believe that we are going to reach that level of perfect results anytime soon with autonomous agents, even if more autonomy to the system is the long term goal. Slow systems are generally unusable unless perfect, which is why we have seen capabilities like autocomplete requiring a sub-second latency for a developer to even consider a suggestion (in fact, our median autocomplete latency is ~300ms!).
For example, “agentic” products today take an hour to do something that a decent engineer would take five minutes to do, and it isn’t truly autonomous - you still have to check back in periodically to “chat” with it and coax it into completing the desired task. We believe there may be value in this approach for people new to software development, but this won’t give existing developers more leverage, which is our goal. For folks who know how to code, such a user experience would be frustrating and therefore, likely unappealing.
This gets back to the opening statement. It would be much better to have a very fast system that gets to similar levels of accuracy that the developer could interact and iterate with. So, we focused on latency to make the value proposition from a tool that looks good on paper to a tool that works in practice, which is perhaps nonintuitively a harder problem. We trained our own foundational models for Riptide that are better than GPT-4 at these tasks. We parallelized and batched the compute required for Riptide across hundreds of GPUs to make the full reasoning happen in the matter of seconds. We built out low-level capabilities like speculative decoding to make components like instruction-following so fast it doesn’t feel real time. In short, we optimized everything about the system without sacrificing on quality.
Given the number of tokens of code being processed and the sizes of models being used, we can compute what the corresponding latency and costs would be if we instead used third-party APIs for all of the LLM calls (with likely worse quality due to the models not being custom-built for these tasks). Note that all latencies and costs for competitive models are computed using the highest rate limit tiers available, or, in the case of the cost of Llama3.1 models, the best pricing out of Deepinfra, Lepton AI, Fireworks, Together.ai, OctoAI, and Groq.
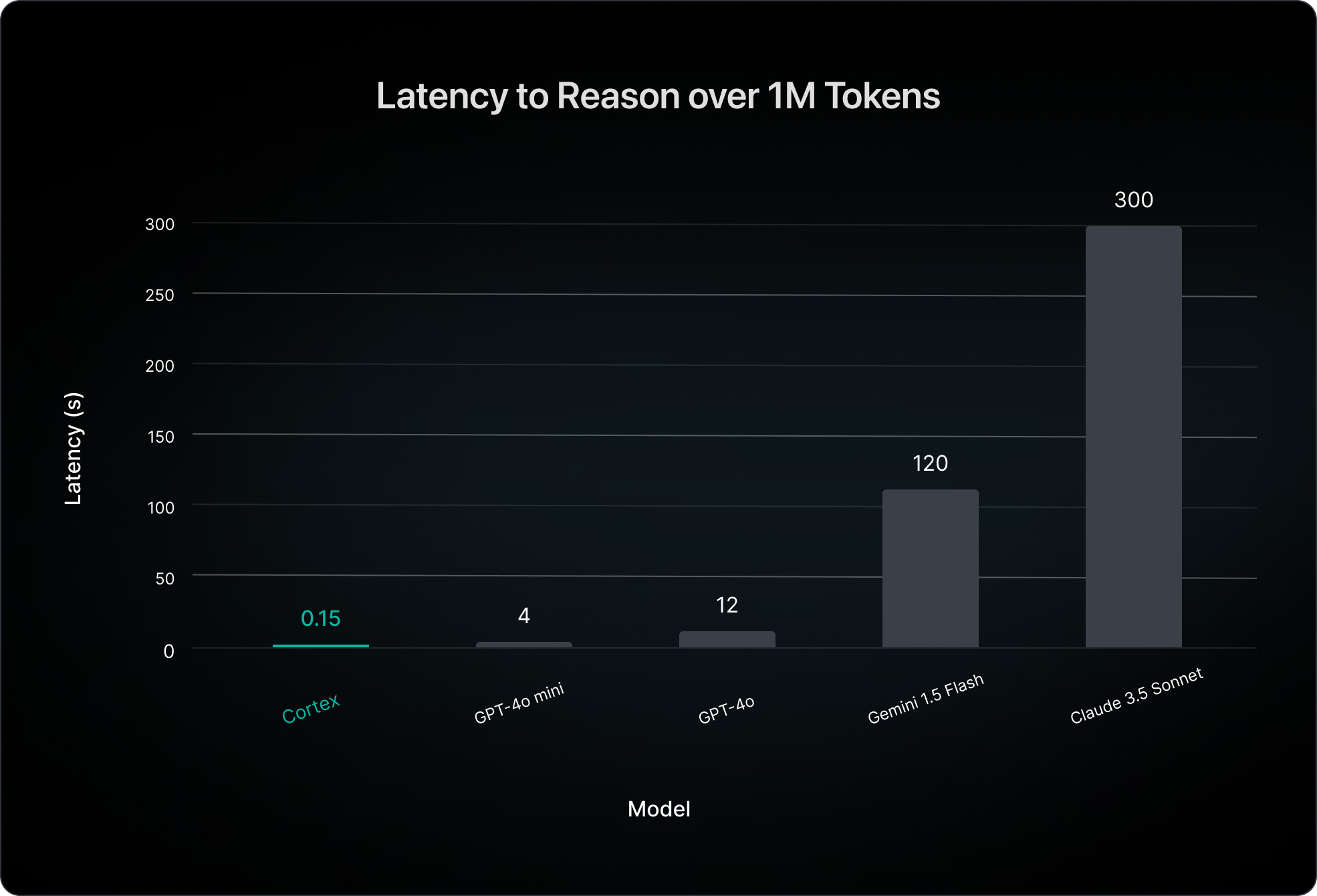
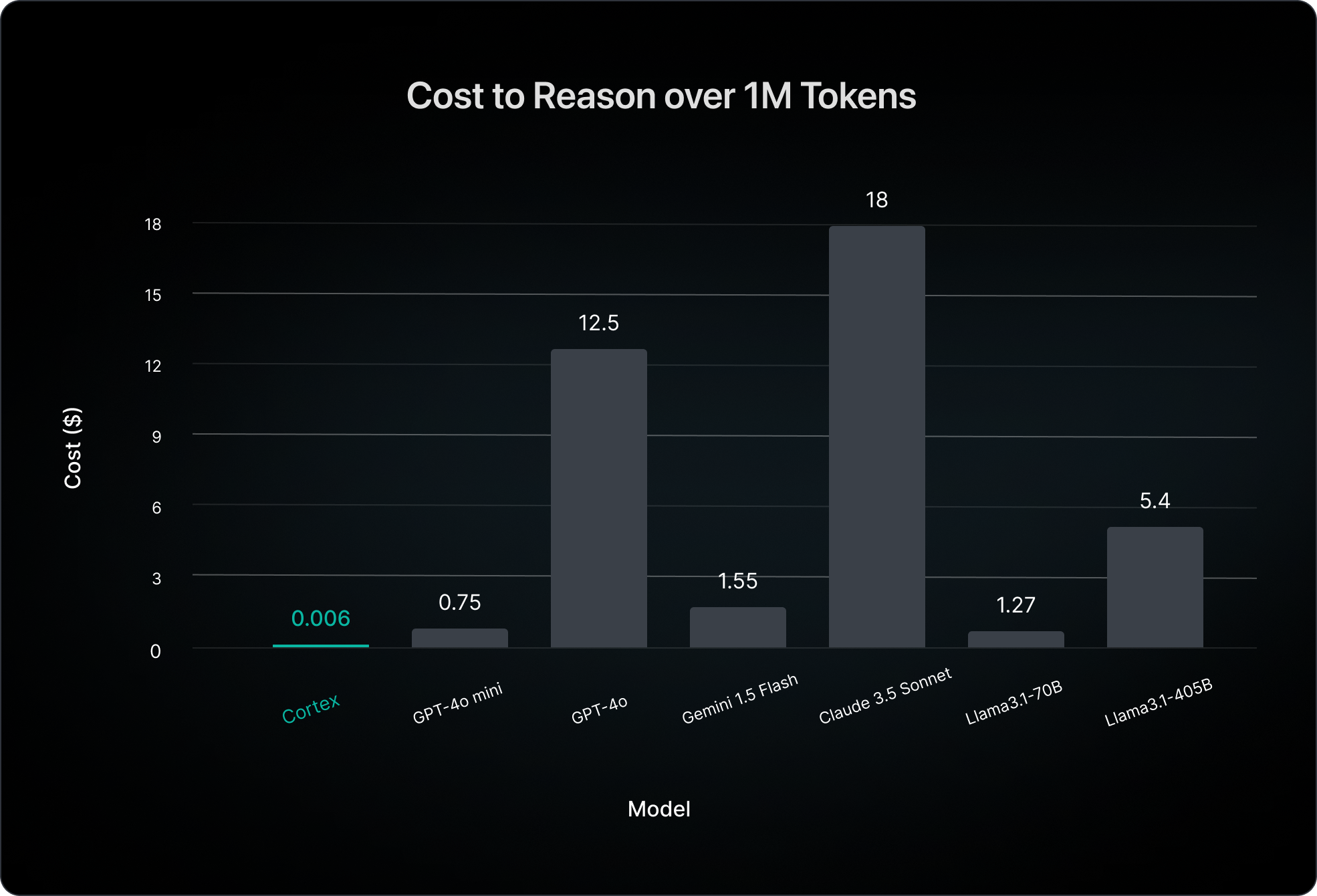
The reality is that the future of this space will depend on more powerful models and more effective use of compute, and that is why we are confident in our ability to lead in this space, as none of our major competitors have the model training or serving expertise to be able to replicate this.
Breakthrough #3: Human-in-the-Loop UX
If the AI fails fast but can explain what it is doing, then a human can get even more value by being able to correct the AI to course correct quickly to successful, useful results.
Due to recent demoware and “thought leader” announcements, there seems to be a belief that to achieve such “pull request level” of intelligence, we need automated AI agents building complex systems without a human-in-the-loop, bringing the end of software engineering as a profession. However, that is not how we see it. We are not interested in replacing humans. We believe the best and ideal end state of AI maximizes human potential.
When the Internet came about, the ideal end-state to knowledge retrieval was not to have one or more “virtual librarians” go off for hours and retrieve the exact content that you were looking for. The ideal end-state was Google. It is fast and very accurate, though not perfect. Yes, a novice in the field of query gets value from Google, but so can an expert in the field, by using their own knowledge to take Google’s approximately correct results to the finish line. This fusion of expertise to create multiplicative effects at the boundary of human capability is why the human species is smarter and more capable because Google exists. Technology that runs quickly with a human-in-the-loop is what has historically advanced knowledge work. This, we admit, doesn’t sound as polarizing or fear-inducing as the doomsday Twitter demos. But that is exactly what those are - demos.
All of our breakthroughs in latency will allow us to fundamentally enable novel human-in-the-loop user experiences.
The truth is that AI is not perfect. We are some of the biggest AI optimists you will find, but we won’t delude ourselves out of reality. AI will get closer to perfect over time, but as we mentioned in the previous section, it will always make some mistakes in some fraction of scenarios. Keeping a developer in the flow helps shift from a product that is a coin flip to a product that a developer can iterate with.
This also helps us avoid requiring code execution to close the loop between AI-generated results and feedback to iterate on the results, which can be slow, incomplete, and incredibly hard to instrument in complex enterprise environments. The human becomes the feedback loop.
There are a number of places a developer can insert feedback, provided that the process runs quickly:
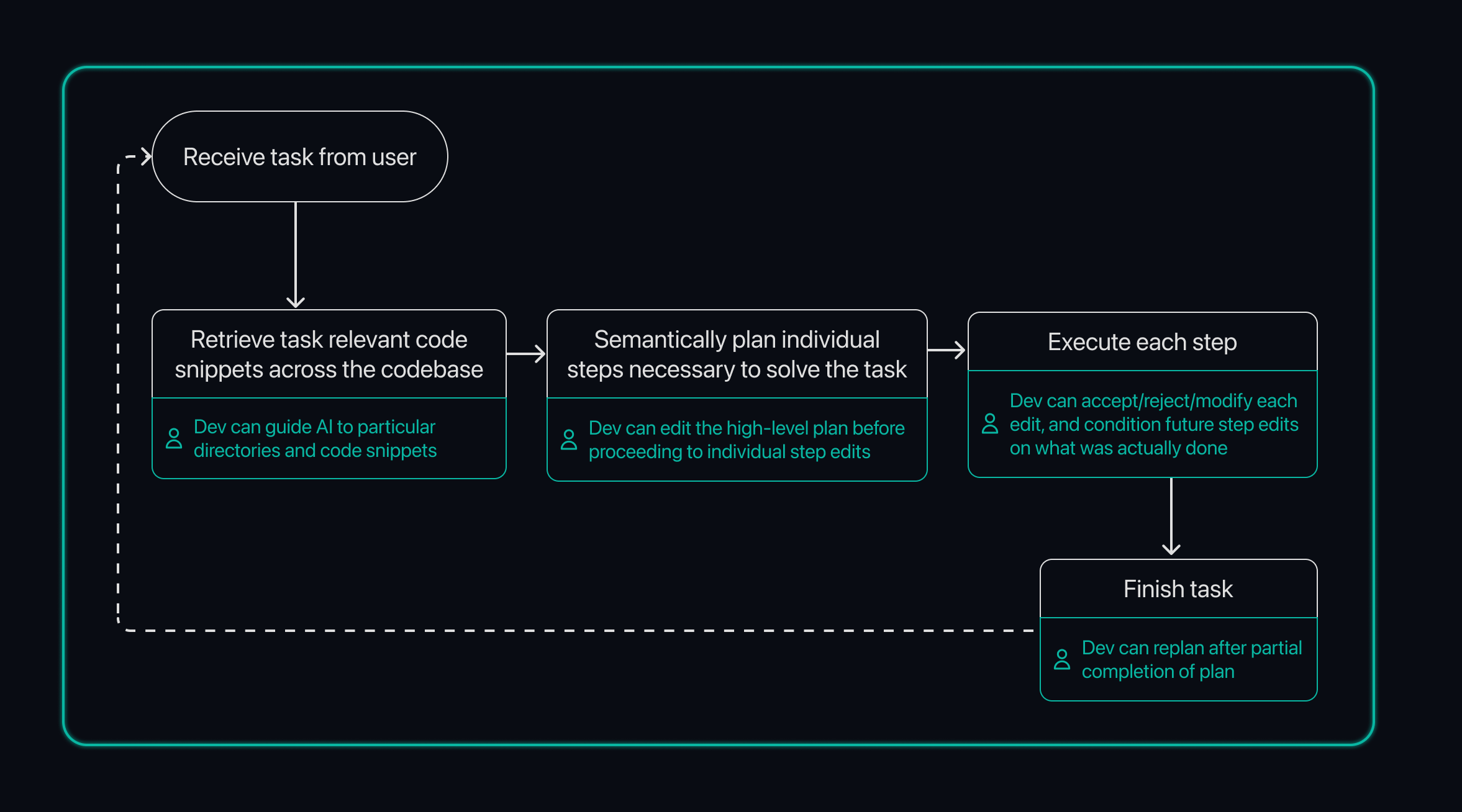
If developers do not get value from a human-in-the-loop UX, it is doubtful the quality of results are good enough for a fully autonomous system. However, as we identify tasks where the results are consistently good, we will have the confidence to bring those to fully automated workflows. This is simply a realistic way of delivering on the bigger goals that we have as a company.
Riptide is a huge step forwards in helping developers solve more complex problems faster, allowing them to approach challenges in a more powerful way than they were able to before with Codeium.
We have already started integrating Riptide into our existing products. For example, we can use Riptide to better identify relevant context items for any Chat message in a second. Our A/B tests show that using Riptide as the underlying reasoning engine for Chat has a massive performance benefit over Copilot-level context awareness.
Cascade: Multi-Step Tasks
Cascade is our first prototype product that is built from first principles with Riptide in mind. Cascade is a rapid, intuitive, human-in-the-loop tool that directly exposes the retrieve-plan-execute framework of Riptide in the IDE. Here are some of the things that Cascade can do:
As a disclaimer that we put with any Prototype capability, we do still believe we are in early stages of this technology and don’t promise perfection, and we know it cannot solve many large scale reasoning tasks today with reasonable accuracy. The best way to think about Cascade today is a more powerful version of Codeium Command where you can give instructions to make coordinated changes across multiple locations. We will continue to allow people off of our waitlist as we iterate and improve on the technology.
We are experimenting with new human-in-the-loop interaction flows that are native to Cascade, and are hoping to get feedback on whether these are intuitive and valuable:
- Scan defined subset of repository and investigate the retrieved contextual items
- Edit the initial semantic plan before starting to generate individual edits
- Preview each diff individually, directly in the editor
- Accept/reject any one diff individually (with any future diff generations conditioned on whether you accepted)
- Use our command “follow-up” UI to redo an individual command with a different instruction
- Modify a diff individually (with any future diff generations conditioned on your edits)
- Complete a subset of steps, then replan the remaining steps because you learned something that changes your approach a bit along the way
Cascade has been designed with quality, latency, and interactivity as joint first principles.
Forge: Code Review Assistance
Any professional developer will tell you that independently writing code is just a part of the job. Companies build software engineering teams because there is a need for collaboration to successfully build complex systems. On a day to day, this collaboration manifests itself clearly in the code review process, either via leaving comments on someone else’s proposed changes (often called a pull request) or responding to changes that someone else has left on your pull requests. Pull request cycle time, i.e. the amount of time it takes between a pull request being opened to being closed, is an incredibly critical factor to how fast a company can ship, which is why large organizations spend a lot of time optimizing this process.
One of our goals at Codeium is to help accelerate every part of the software development life cycle with AI, because you only provide leverage overall to a developer if you provide that same level of leverage across all of their tasks.
Forge is our code review assistant that reduces code review cycle times and improves code review culture. Forge helps assist the reviewer through multiple AI-powered features, including:
- AI Explanations & AI Chat: Explanations of changes in a pull request, both at a macro and a more targeted level, which helps augment what may normally be an imperfect or incomplete pull request summary. Also interactively chat directly in the SCM to minimize context switching..
- AI Comment Resolution: AI-generation of a code change proposal that would resolve a comment, which brings the reviewer into the authoring process and reduces the awkward dance between reviewer and author on back-and-forths. Instead of just leaving a comment, the reviewer can easily leave a comment and a suggestion on how they expect to see the comment addressed.
- GIFs: Okay, this one has nothing to do with AI, but we couldn’t help adding GIFs. We love reviewing PRs now.
There are many more features not shown, such as prompt engineering and AI-powered autocomplete of the suggested code resolutions, but the best way to see Forge is to try Forge. It is currently available on GitHub SaaS.
The most notable excursion into the code review process so far has been by GitHub Copilot, with their launch of automatic pull request summary generation as part of CopilotX last March, and teased again at GitHub Universe last fall as part of the new Copilot Enterprise tier. We believe this is a minor improvement to the pull request review process, especially in its current iteration, where the current demos show 40+ lines of summary for a 15 line code diff.
The other nuance is that GitHub Copilot’s feature is tied to having GitHub SaaS as the source code management (SCM) tool of choice. The reality is that there is a sizable fraction of enterprises that do not use GitHub, and even more that choose to self-host their GitHub instance for security concerns. The beauty is that we have architected Forge to be SCM agnostic, whether in cloud or self-hosted, and once we build confidence in the value on GitHub SaaS, we will work on integrations with Gitlab, Bitbucket, Perforce, and more.
Forge is another first-of-its-kind system, and expands Codeium beyond the IDE. Forge is able to leverage all of our underlying models and infrastructure to deliver a seamless, high-quality, and performant experience in the code review process.
Guidelines: Encoding Organizational Best Practices
As mentioned at the top, we believe that developers have a lot of potential that Codeium can help unlock, but that organizations have even more untapped potential. At the root, this is because different organizations, by definition of having different end business applications, have bespoke institutional knowledge. Knowledge of a programming language generally transfers from company to company, but knowledge of an internal framework? coding best practices? best use of tools? Not as much.
Today, we are starting to roll out Guidelines, a cross-product, cross-feature paradigm that will help encode organizational best practices. The idea is simple: allow developers with the know-how to define the best practices within the context of use in Codeium. Then, any other developer can automatically pull down these guidelines and apply it to their work, democratizing this knowledge. This brings organizational best practices to the developer at the moment that the developer needs it, rather than having this information siloed in some documentation.
Some example Guidelines could be:
- Prompt Guideline: It is important for the AI to respond in useful ways for the developer, such as responding in a non-English language or follow a certain set of frameworks by default when doing tasks like writing unit tests.
- Custom Context Guideline: Perhaps while working in a particular repository or a specific file type, an organization wants to enforce framework use, common best practices (e.g. do not use lambdas), a natural language to use, etc. Senior developers can define these Guidelines, and developers will then be able to pull them while they are working.
- Context Pinning Guideline: Perhaps while working in a specific application library, it is important to pin a remote repository with some central frameworks, utilities, or components. A senior developer might know this, but a junior developer might not.
- Forge Guideline: It is common to see the same comments around adherence to particular organizational best practices appear over and over again during pull request review. These aren’t simple or generic linters, but defining these Guidelines in Forge can allow for quick automated scanning of potential pitfalls, even by the author who might not know these.
We are launching Context Pinning Guidelines as the first generally available application of the Guidelines concept.
In Forge, we are beta launching Forge Guidelines to power an autoreview bot. The organization can define a list of personalized semantic checks, and the Forge bot will check for each of these Guidelines once a PR is opened. Forge Guidelines are available via waitlist from within the product.
Codeium’s context awareness engine has already led to 5x decreases in onboarding time for many of its enterprise customers, and Guidelines will continue the democratization of institutional knowledge at the point of application. This will be a huge unlock to allow organizations to dream bigger.
Data Connectors: Bringing in Explicit Enterprise Knowledge
Organizations have both explicit and implicit private knowledge. Guidelines handles encoding implicit private knowledge, and today, Codeium’s ability to ingest entire private codebases and provide contextually aware results across repositories is already state-of-the-art in incorporating explicit private knowledge.
However, there are many more private stores of knowledge than just codebases that are useful to developers, even if codebases are the most relevant. This includes tickets, documentation, and other tools. Our goal is to integrate with all of these as Data Connectors to Codeium’s underlying reasoning engines, making every product contextually aware of all of the information that a developer already has access to, allowing us to give the most accurate and relevant results.
Extending our partnership with Atlassian, we are starting to work on Data Connectors with Jira and Confluence. More information is coming soon.
Codeium: Not your ordinary Copilot
We have not yet talked about the improvements that we have been launching on our existing systems, which are used by over 600k developers and 700 companies. And there have been many. At this point, we feel like we have solved the core IDE experience of increasing developer productivity via acceleration of writing code they would know how to write, and are moving on to enabling developers with new reasoning via Riptide, new surfaces via Forge, and new knowledge management via Guidelines and Data Connectors.
To make our approach more clear, let us simply map out the structure of a generic tool, inspired by our analysis of the Human-Tool Interface:
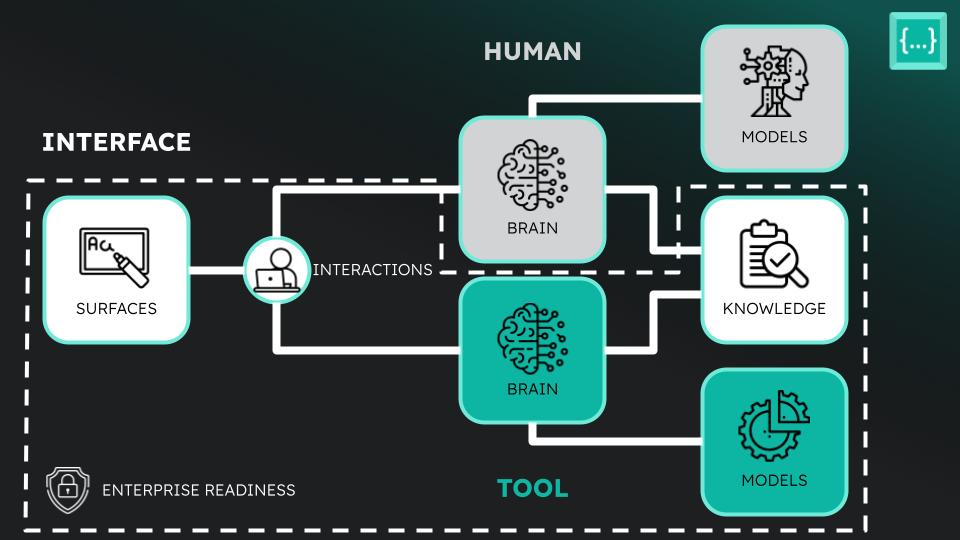
Humans are great because we have brains that can reason and keep state, applying models of how to perform tasks on existing knowledge, and doing this work on surfaces (e.g. IDE, SCM, browser, etc). However, any individual human has limited reasoning and state, as well as an incomplete set of models - the difference between a senior and junior engineer is that the senior engineer simply knows more models, i.e. knows how to do more tasks. This is why we build tools - technology that theoretically has infinite state and reasoning that can use their own underlying models but can be applied on the same set of knowledge. Humans and tools then have interactions over the surfaces, whether it be humans providing inputs to tools or tools giving results back to humans.
The incredible part of the Generative AI wave is that, for the first time, we had models for tools that were pretty high precision on a very large recall of tasks - instead of a SAST tool being really good only at SAST tasks, we had these LLMs that were equally good at writing code and coming up with a recipe. This breakthrough allowed for new forms of interactions to be high quality, like the ChatGPT form factor, by doing clever expanded reasoning, like using previous responses in a conversation as input to the next “prompt”.
The Human-Tool interface is an abstraction that allows us to have a clear vision when it comes to building tools - instead of focusing on just the model, we focus on all aspects that a tool is comprised of in order to drive the most value. We can easily classify each of our workstreams according to how it fits in this abstraction.
At a high level, these are the following components of any tool:
- Models: Methods of generating new information, which are the LLMs themselves today
- Knowledge: Existing information that would be valuable context for the tool (explicit like Data Connectors or implicit like Guidelines)
- Surfaces: The places where people work (editor, chat panel, browser, etc)
- Interactions: The modalities in which a human and tool interact over surfaces (autocomplete, chat, command, etc)
- Brain: Can collect and manage state of the interactions and reason upon it in conjunction with available knowledge using the tool’s models
- Enterprise Readiness: The systems and certifications surrounding the execution of the tool that allow it to be usable, not just valuable
We are the only vertically integrated solution, and this is because we have recognized that we must think of all of the components for any project:
- A new model must think about effects on the latency of the corresponding interaction
- A new knowledge source must think about access controls in enterprise readiness
- A new surface must think about how its interactions can be captured in the brain’s state
Because of this, a tool is only as good as its weakest component, and we uniquely do not lag on any axis.
So, what have we done with our existing, core in-IDE offering?
- Models: We never call ourselves a model company, but we train models for workloads when it is required to drive value, as we found we had to do for Autocomplete and Command (full story on building models for Command here). For workloads like Chat, we have provided optionality for Llama3.1, OpenAI, and Gemini so users can choose between faster, smaller models that can reason about your codebase incredibly well or a slower, larger model for general questions and reasoning.
- Knowledge: Build parsing, embedding, and indexing logic for code stored on any Source Code Management tool (GitHub, GitLab, Bitbucket, Perforce, Gerrit, etc, both cloud or self-hosted) so that we have access to your existing codebases.
- Surfaces: Extensions on over 40 IDEs, the most availability of any code assistant. We also have the most coverage of our interactions across surfaces (e.g. Chat not just in Visual Studio Code and Visual Studio, but also Jetbrains and Eclipse).
- Interactions: Incredibly low latency Autocomplete, Chat, and Command modalities to provide passive, exploratory, and instructive interactions respectively. Intuitive ways to guide the AI through at-mentions, context pinning, and custom chat context.
- Brain: State-of-the-art context awareness engine that even has multi-repository context awareness, which increases the amount of code accepted by 35% over just a base system with limited reasoning (e.g. only open tabs).
- Enterprise Readiness: A very long list from multiple deployment options (SaaS, Hybrid), most detailed analytics dashboards with metrics that are actually meaningful, not training on non-permissively licensed code, respecting existing access controls, attribution and audit logging, and more. We are very confident in saying that Codeium is the most enterprise-ready code assistant in the market.
Our leadership in the core code assistant space has been repeatedly recognized:
- Forbes AI 50: Only AI code assistant on the list
- Marketplace Ratings: Only 5-star AI code assistant
- StackOverflow Surveys: Voted as the AI tool that drives the most productivity and satisfaction
This core product is called Codeium. By itself, Codeium is more powerful than any other in-IDE “copilot,” and the underlying LLMs and knowledge-understanding systems are fundamental components that have been (and will continue to be) reused in our next series of products, such as Forge.
Codeium will continue to improve, such as integrating Riptide and Guidelines, developing and deploying bigger and better models, and using additional knowledge sources such as Jira and Confluence. We are excited about all of the advances that will come next.
Concluding Thoughts
Many of our competitors frame themselves as “copilots,” but in reality a developer doesn’t need another developer to be able to do bigger, more complex tasks. Giving a pilot a copilot does not mean they can now fly a rocket ship. Instead of giving developers a copilot, we are giving them a more advanced cockpit.
Quite transparently, our goal is not to be a GitHub Copilot alternative. If that was the case, we would never have started the Codeium journey. We started Codeium because tools like Copilot showed us the tip of the iceberg of what is possible if you apply AI to software development, but we know that the real value is in unlocking untapped leverage to developers and organizations. We cannot imagine today what humans are capable of building tomorrow, but Codeium will be the one to enable them to do so. To allow them to dream bigger.