tl;dr For enterprise customers, we have enabled server-side computation and storage of derived information used by Codeium’s context awareness engine. This unlocks context awareness across larger repositories and over multiple repositories, further increasing the quality of Codeium’s suggestions, especially for larger organizations.
What is Context Awareness and Why Should We Care?
We talk a lot on our blog and with customers about the idea of personalization. At the core, the idea is that a generic system that has only seen public information will not give the highest quality suggestions and answers when working in a private environment, such as a codebase that has never seen the light of day (at least to these foundational models). It is not a groundbreaking idea by any means. There are two main ways to personalize an LLM-based system - you could modify the model ahead-of-time, a process often referred to as fine-tuning, or you could be smart about what private information you pass into the limited context length that these LLMs have, an approach we often refer to as “context awareness.” The popularly discussed technique for context awareness is Retrieval Augmented Generation (RAG), which as its name suggests, involves precomputing some sort of index of snippets all of the available private information, retrieving the most relevant elements at generation time, and inserting these snippets alongside the LLM prompt as “context” for reference.
Fine-tuning gets a lot of press, but we have found that the context awareness piece is often much more important and valuable. This is not to say that a personalized system shouldn’t employ both techniques, and we have built both for Codeium, but the only times we have empirically seen fine-tuning create a noticeable quality improvement have been with private domain specific or publicly rare languages. The intuition here is that training on an additional tens of millions of lines of a popular language/package won’t move the needle (our base model has been trained on trillions of tokens of code), and if the eventual goal is to retrieve particular snippets, then you should depend on the half of personalization that does exactly that.
The other misconception is that context retrieval is not a real problem that needs to be solved long term because eventually models will be able to take arbitrarily large prompts (e.g. massive context lengths), so there is no need to be picky and choosy about what you pass in. This is wrong on many levels, from the prohibitive cost and latency involved in doing so, to the fact that experimentation is suggest that retrieval may be unequal across the context window for such long-context models today. So, in some form, it is good to know what is relevant when making an inference, which seems consistent with intuition.
Great, now that we have established that context awareness is important, how do we do it well for code?
Codeium’s Approach to Context Awareness So Far
When we surveyed how other tools did context awareness, we were pretty disappointed. The context being passed in was often just from the same file, and the most advanced would look at code in open tabs. While this might work for other modalities, it doesn’t for code - code is an incredibly distributed knowledge store - just think of how common a developer traces through chains of import statements. The distributed nature is why we built a full embedding-based retrieval system, leveraging the structured nature of code to smartly parse code to identify the blocks to individually embed and index. Then at retrieval time, we built a lot of smart logic to pull context from a number of different sources - not just the current and open tabs, but also files in the same directory, files referenced in important statements, and of course, this full repository embedding-based index. All of the context from all of these sources still cannot fit in a limited context length, so we rerank based on source type and strength of match, which is the secret sauce. This is an incredibly simplified description of the indexing-retrieval logic, with some more complex details including:
- During Autocomplete, Codeium can do an exact lookup of a function definition by name if being called because we smartly parse semantic blocks such as functions and classes during the indexing process.
- During Chat, a developer can use the @ symbol to @-mention these semantic blocks and we can automatically pull in the relevant context, again due to smart parsing and indexing of semantic blocks.
- We use a hybrid Lucene-style keyword retrieval, which weights by how rare keywords are in the corpus, alongside the embedding-based retrieval. Add in weighting according to intent such as “is file open” and a bunch of other factors, and you end up with a much more complex reranking system than a naive Jaccard-based similarity, which underpins other tools such as GitHub Copilot.
This state-of-the-art context awareness system performed incredibly well, with our A/B testing showing that our first deployment caused a massive 27% increase in code completed through a combination of increased acceptance rate and increased length of accepted and unedited suggestions. To demonstrate the power, we will now use the @-mention capability in our Chat experience, allowing users to guide the context awareness system to retrieve and highly-weight particular blocks of code as context for the LLM. Here’s us comparing two functions, understanding their subtle differences without having to read through their implementations:
Where the Implementation Breaks Down
In theory, this approach is pretty great, but the devil is in the implementation details. We started by implementing this for our SaaS users so that we could easily control any A/B tests, but the tricky part is that we don’t have direct access to the developer’s repositories. So, we got around this by noticing when a developer checks out a repository into their IDE, we start doing the preprocessing to generate the index, and save that index locally on the developer’s machine. Full repository context awareness? Solved. Heck, we could even personally maintain embedding-based indices of a bunch of popular open source repositories, and let developers @-mention information from these repositories as well in their Chat messages, so we went ahead and did that. Here’s an example of mentioning Material UI to write a React component for our repository:
But what if a company has not adopted a monorepo setup and has code distributed across many private repositories? It is easy to imagine such situations, such as utility libraries living in one repository, but then a project repository clearly wanting to leverage the utilities. Or just starting a new repository from scratch when there is nothing to even pull context from in that particular checked-out repository. Right now, we rely on the developer having checked out a repository to even think about parsing it, and then locally doing the preprocessing, but this is not something we can reliably rely on. We did not have built-in “multi repository” context awareness.
On top of this, what if a company has just a lot of code (even just millions of lines)? Embeddings are not that large, but still, there is a limit on how large of an index we can store on a developer’s machine without throttling the system, which in turn puts a limit on the size of the repository we can have full context over. We did not have a concept of a “remote index” that a client machine can refer to, while only maintaining an “index diff” based on the local code diff that the remote index can be combined with on the fly. This would have the added benefit that if you have many developers in the same repository, there would be a significantly reduced amount of duplicate indexing.
Remote Indexing and Multi-Repository Context Awareness
Our big accomplishment has been to solve these exact implementation problems by building a remote indexing system, which will then enable large repo and multi-repo context awareness. To build this, we already had a way for an admin to provide read access tokens of repositories to the Codeium instance for fine-tuning purposes. We leveraged this system again to let an admin specify a bunch of repositories to remotely index, after which developers would have access to these repositories for context awareness, no matter which repository they actually have checked out. The UX for the admin is quite straightforward, with no annoying steps like integrating with a build system - just provide the read access token, some parameters on how frequently you want to reindex, and whether you want to garbage collect old indices, and you are good to go:
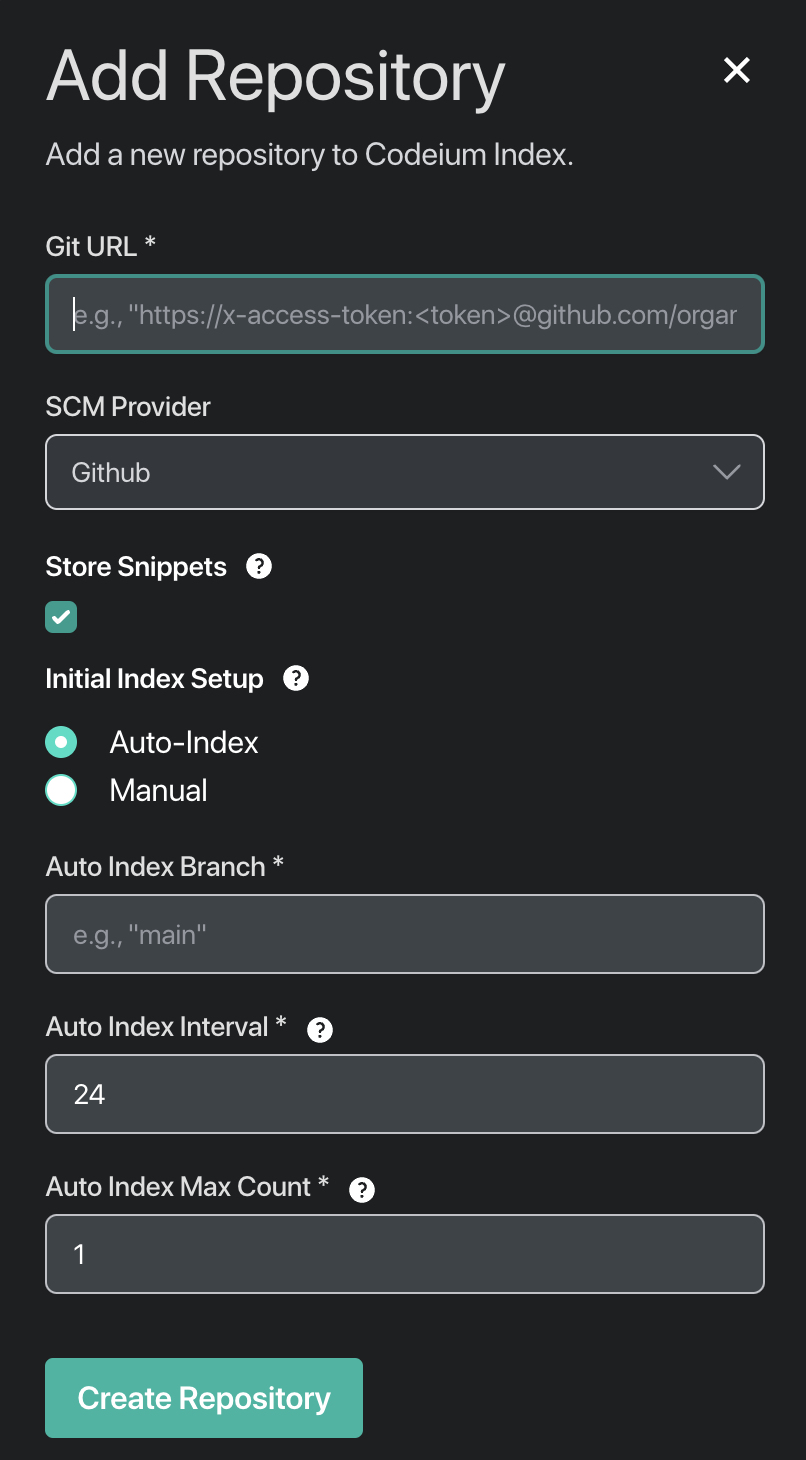
And to prove that this works, here is an example of us using the @-mention functionality on a block of code from a different, private repository that was also indexed:
Next Steps
The first large project is getting this capability to our SaaS customers, where today we guarantee that we have zero-data retention (e.g. our compute is stateless, after inference any code snippets or prompts are immediately deleted and never serialized, stored, or persisted). We are actively thinking through alternate various deployment options for when there may be varying sensitivities to external persistance across different types of information.
However, past this engineering problem, we are excited what this core competency of remote indexing will allow us to do. We can obviously integrate these private remote indices into private instances of Codeium Live, or use this out-of-IDE understanding of existing knowledge in new out-of-IDE capabilities, such as PR review.
Finally, we are actively thinking of what the next generation of retrieval looks like. Sure, our retrieval system is far ahead of what other tools have deployed publicly, but we think there are limits to what single-shot RAG can achieve, and are working on ways to leverage compute to process existing knowledge more at query time.
Reach out if you have codebases with millions of lines of code: