A few months ago, we launched a prototype feature called Codeium Command, an instruction-driven modality to perform refactors and edits inline. Today, we walk through the iteration and improvements we have made to Command to bring it to a state where we are confident in its capability, thereby removing the prototype tag and committing to long-term support and expansion to other IDEs.
Background on Codeium Command
As a reminder, Codeium Command fills a gap in interactions a developer would want with their IDE. Autocomplete is passive and in-editor while Chat is instructive but in a separate panel. Often, we want to provide an instruction to the AI in the flow of the editor, and until Command, developers had to rely on writing temporary comments in the style of instructions hoping that will trigger the Autocomplete model to comply (even though that isn’t how the Autocomplete model is trained). Command gives developers the ability to instruct the AI to perform tasks within the editor (shortcut: Command-I):
Codeium 1.0: Using GPT-3.5
With our realism on Gen AI product development, we wanted to get the Command modality out quickly to our hundreds of thousands of individual plan users so that we could get quick feedback and iterate with data. To do so, we just used the GPT-3.5 model as our backing LLM. We always consider ourselves an application company, so if there is a model that does really well for a particular task, we won’t waste time trying to reinvent the wheel just to say that we made the model. The results were not very encouraging:
So what went wrong with this first iteration of Command? Probably a number of things, but the most obvious was the model. GPT-3.5 is fast, which was critical because we couldn’t have developers waiting for too long before returning any results. But at the same time, it liked to be verbose.
For example, when we tried giving a Command of “write a docstring” to a block of code with the cursor in between the function header and the body, GPT-3.5 gave the following response:
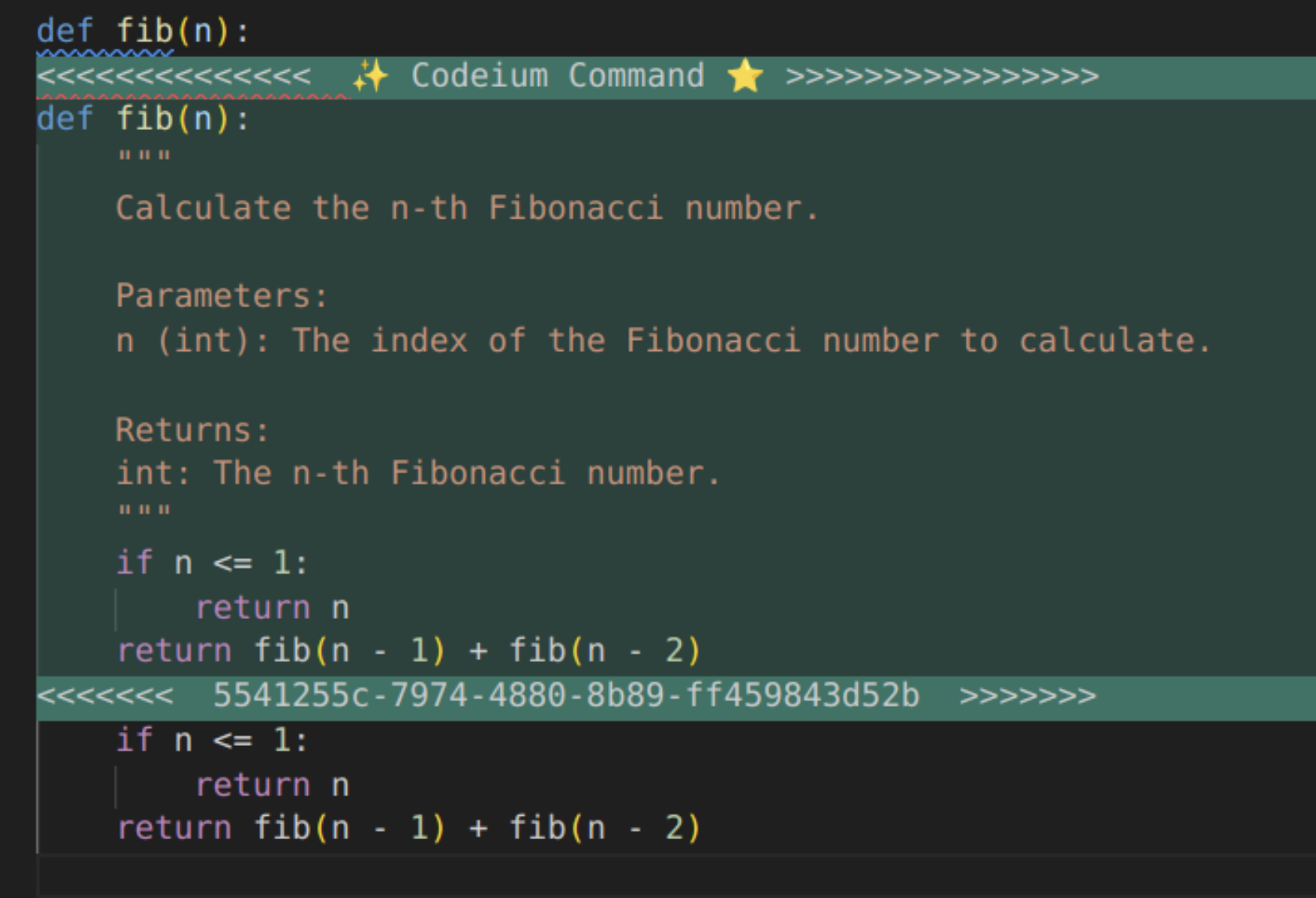
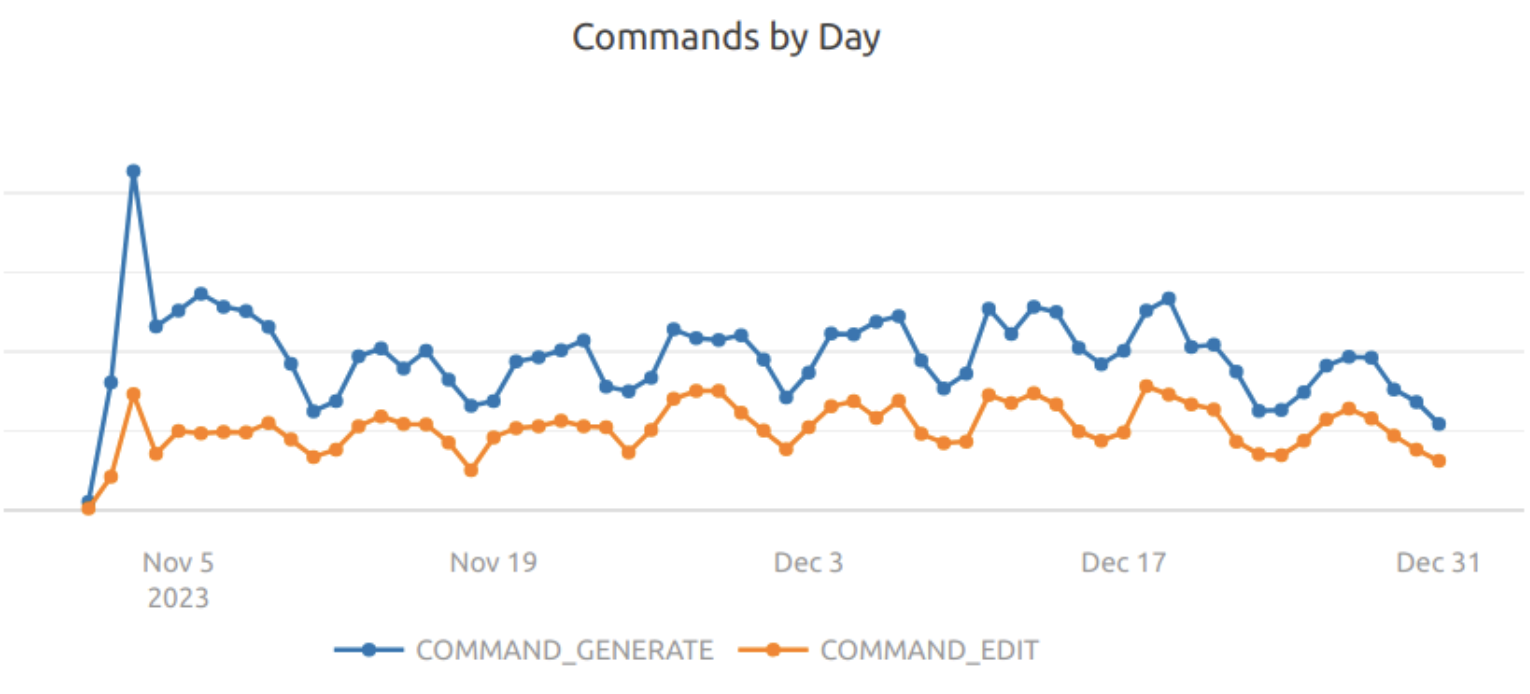
It is wordy, but worse was that it would more often repeat the prefix or suffix (or parts of it), as seen above. Prompt engineering wasn’t great at curbing the model’s innate behavior and eventually we found ourselves having to write decently complex heuristics to deal with and truncate these scenarios, but that was not perfect either. The underlying quality of suggestions either were just not that great, though that is harder to show in a screenshot. Given that we generally have an aversion to excessive “prompt engineering” or heuristics since neither outlast improvements or changes in underlying models, this was not very promising. This underlying tendency of GPT-3.5, even with all of the hacks around it, led to pretty poor acceptance rates over the first month of Beta:
- 76% on “edit” tasks (e.g. commands where the user highlighted some code to do an inline refactor over)
- 66% on “generate” tasks (e.g. commands where the user did not highlight code, but just provided an instruction to generate net new code or documentation)
These are likely overestimations on the real value of Command because these just captured whether or not a user accepted the suggestion, but not if they deleted or edited a lot of the suggestion afterwards.
Codeium 2.0: Using GPT-4
It turns out that GPT-4 actually is a lot less likely to have this tendency, and is much more predictable and higher-quality in its outputs. So, as a natural second version, we swapped out the underlying LLM to GPT-4 turbo. The results? Well, our acceptance rate went up to 84% on “edit” tasks and 80% on “generate” tasks. Better, but this still not lead to a very promising adoption over the next couple of months, where adoption increased by roughly 50% over the period:
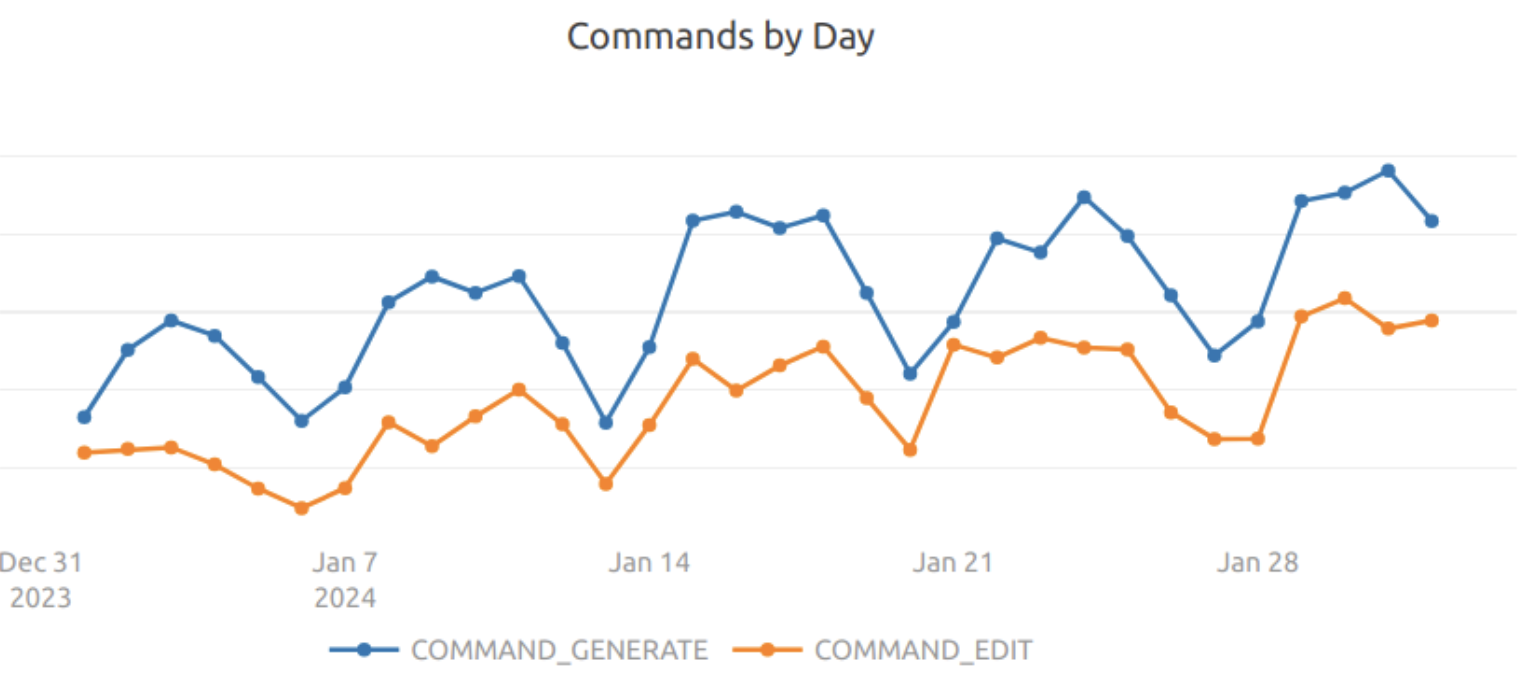
It was easy to guess the culprit for poor adoption of Command with GPT-4. Even though the acceptance rate of shown diffs was higher than with GPT-3.5, significantly fewer developers were willing to wait the significantly higher latency to get a suggestion. This is a common feedback rate vs acceptance rate tradeoff that we called out when talking about our golden metrics such as Characters per Opportunity for Autocomplete.
So we came to the position where there was no existing LLM that would simultaneously be fast, be high enough quality, and not ramble. We realized that purely to actually drive value, we needed to train our own instruction-following code-diff generating model. GPT-3.5 and GPT-4 are good models, but just like with Autocomplete and a number of tasks covered by Chat, we found ourselves in the position where these models were just not good enough.
Command 3.0: In-House Model
At Codeium, we are laser focused on building the best possible product, and that means having the expertise and capability to train our own code foundation models. We just always make sure to hold our feet to the fire and be honest with ourselves if off-the-shelf models could outperform us, and in this case, that was clearly not true. We decided to train our own instruction-following code foundation model for Command.
We realized that on public repositories, we have a history of commits as well as code diffs associated with those commits. Those became the basis of a training set (after a lot of sanitization), where we could map instruction-like commands (commit messages) to inline refactors (corresponding diffs). After training our model and applying a few latency-improving infrastructure tricks like speculative decoding, we ended up with a model that is both better than GPT-4 at this particular task and runs 4x faster than GPT-4 turbo or GPT-4o. Immediately, we saw growth in Command usage, with usage increasing more than 250% over the span of a few weeks:
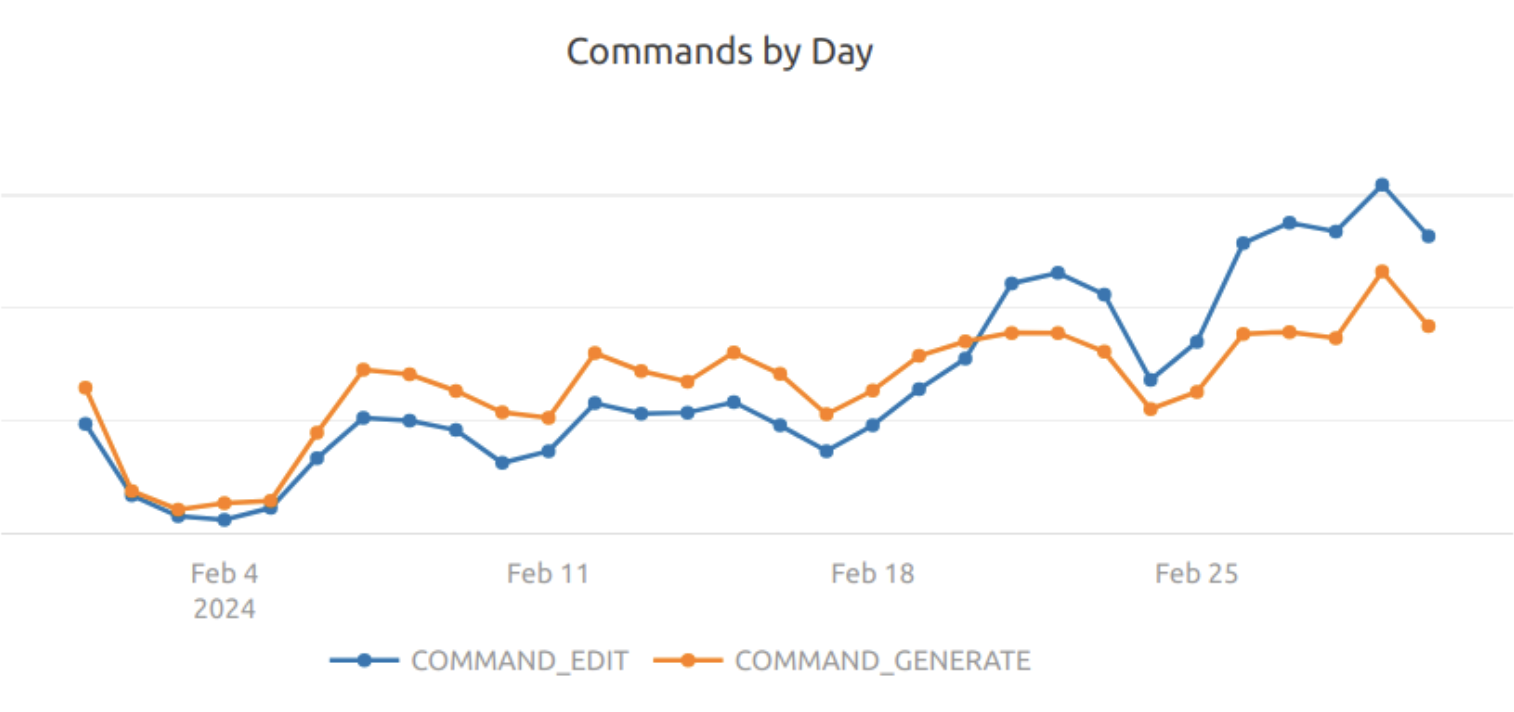
Improvements to Discoverability & Growth
At this point, we knew that we finally had something that resonated with users, because even with zero effort toward bringing eyeballs to this modality (beyond Codeium University and some one-off blog posts), more and more people were using Command, and importantly, continuing to use Command (e.g. low churn on the feature).
So, we took it up a notch to make it clear that Command was the ideal workflow when doing inline refactors. When a user highlighted a block of code, we show a CodeLens that would bring up the Command window:
We made the standard refactor CodeLens on top of functions and classes to trigger Command rather than Chat:
We made it easier to iterate on Command instructions with follow-ups:
And the adoption just kept going higher:
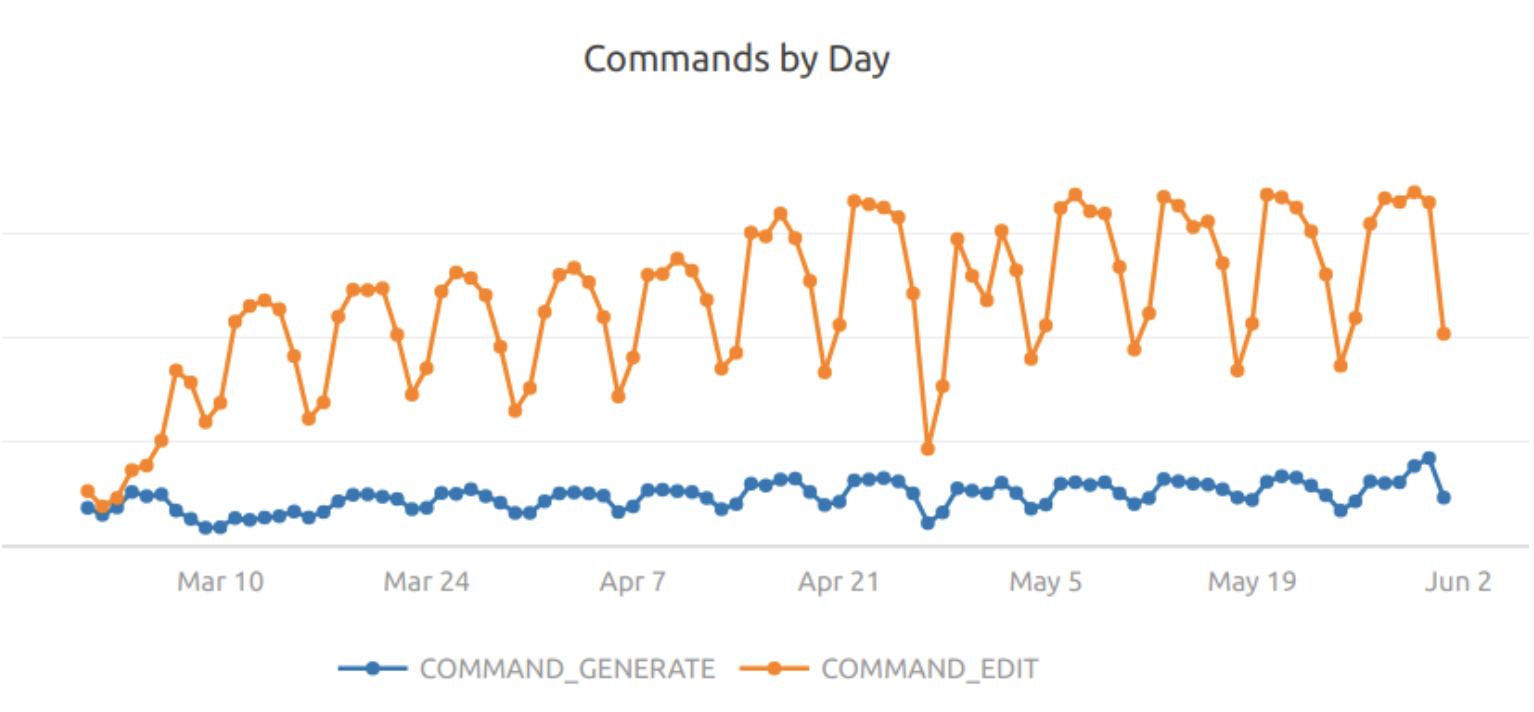
We have almost reached 100k active users on Command, and after some incredibly rapid initial growth, Codeium usage has been matching the growth of the overall Codeium extension, suggesting that new users are getting the same value of the modality as existing ones.
Next Steps & Conclusion
We have already done a lot more with Command since the start of this growth. We have successfully trained models that can support both the Chat and Command functionalities without degradation in quality for either task. We have ported Command over to JetBrains, and will be looking to integrate it into more IDEs in the future. We have further improved the data sets and models based on the tasks that we have seen users actually use Command for.
In the future, Command is reflective of a new core competency of Codeium on instruction-following, which will be leveraged across more in-IDE products and even new out-of-IDE products. Stay tuned, and try Command out in VS Code or JetBrains today: