Software Licenses and Generative AI
Sometimes, if you look at a public repository, you will find a LICENSE file with a bunch of legal jargon that corresponds to some particular category of software license, such as MIT or GPL. In the world of public code, the majority of code does not have these licenses, but those that do can be split in two categories - permissive and non-permissive (also called copyleft). Permissive licenses such as MIT and Apache mean that a developer can legally use that code for even commercial purposes, while non-permissive licenses such as GPL and LGPL mean that you must share your source code. Violating this latter condition is not just a social faux pas, it has real legal ramifications.
Until the age of LLMs, enforcing this has been pretty clear - if code looks like some non-permissive code, then the person who copied the code in without permission could be held liable. But with LLMs, if a model has been trained with non-permissive code and spits it out during inference, and the developer accepts it unknowingly, then the developer (or company) can be held liable even though there was no malicious intent.
This is a crucial problem for any AI code generation tool wishing to sell this technology to companies. Of course, unlimited indemnity on the generated code is a must, but how can a vendor truly minimize the chances of this happening and therefore minimize the chance of triggering the indemnity clause in legal contracts?
Proactive vs Reactive Compliance
There are two ways of maximizing compliance, and we call them proactive and reactive, Proactive means handling this licensing issue top-of-funnel, at training time via filters on the training data, while reactive means handling this licensing issue bottom-of-funnel, at post-inference time via filters on the suggested code.
Earlier, we published a blog post on how our competitors are investing solely on the reactive side, with solutions that are so brittle that they do not work in practice. The reality is that doing any post-generation filtering is a hard problem, and proactive filtering should be a requirement for any tool that is serious about compliance. For example, at Codeium, we don’t just filter out public code that is explicitly non-permissively licensed from our training data, but we also perform edit distance matching between the remaining code and the explicitly licensed and remove those close matches as well (in case someone copied non-permissively licensed code into another repository without properly attributing it themselves).
That all being said, LLMs are still ML models. They are probabilistic in nature. Even if we don’t train on non-permissively licensed code, there is still an infinitesimally small chance that the LLM generates a series of tokens that is an exact or close enough match to non-permissively licensed code. So, we decided that smart, reactive compliance is also required if we are to take this seriously.
Post-Generation Attribution
The high-level approach to post-generation attribution is to precompute a large database of hashes (e.g. fingerprints) across all public codebases, whether or not we ended up training or not training on them. At inference time, after a suggestion is produced, we first compute a fingerprint of it in the same manner, and if it matches any of the precomputed fingerprints, we recognize that there is some existing code that we need to attribute to in some manner. Of course, this all needs to happen very quickly as autocomplete has a tight latency budget.
Codeium’s attribution differs from others, such as GitHub Copilot and Amazon CodeWhisperer, in the sense that we perform these fingerprints at the per-line basis and perform a more complex algorithm across pairs of fingerprints between the suggestion and public code. Other products perform a very simple “exact string matching” across 150 or so characters to see if there is a match, but there are very simple cases where this breaks down, such as if there are gaps in the matching block of code (e.g. some extra comments or logic blocks or minor naming changes). Codeium’s attribution is more robust to these tweaks to the original code.
Filters and Audit Logs
Note that we haven’t yet mentioned what we can do with a positive attribution. Today, we have automated filters for both non-permissively licensed and unlicensed code, which means that we will not show such suggestions, as well as an opt-in for permissively licensed code (by default, you may get suggestions that match such code, but can choose to filter those out too). This is similar behavior to our competitors. Note that this applies particularly for Autocomplete, and code produced in Chat may not be suppressed.
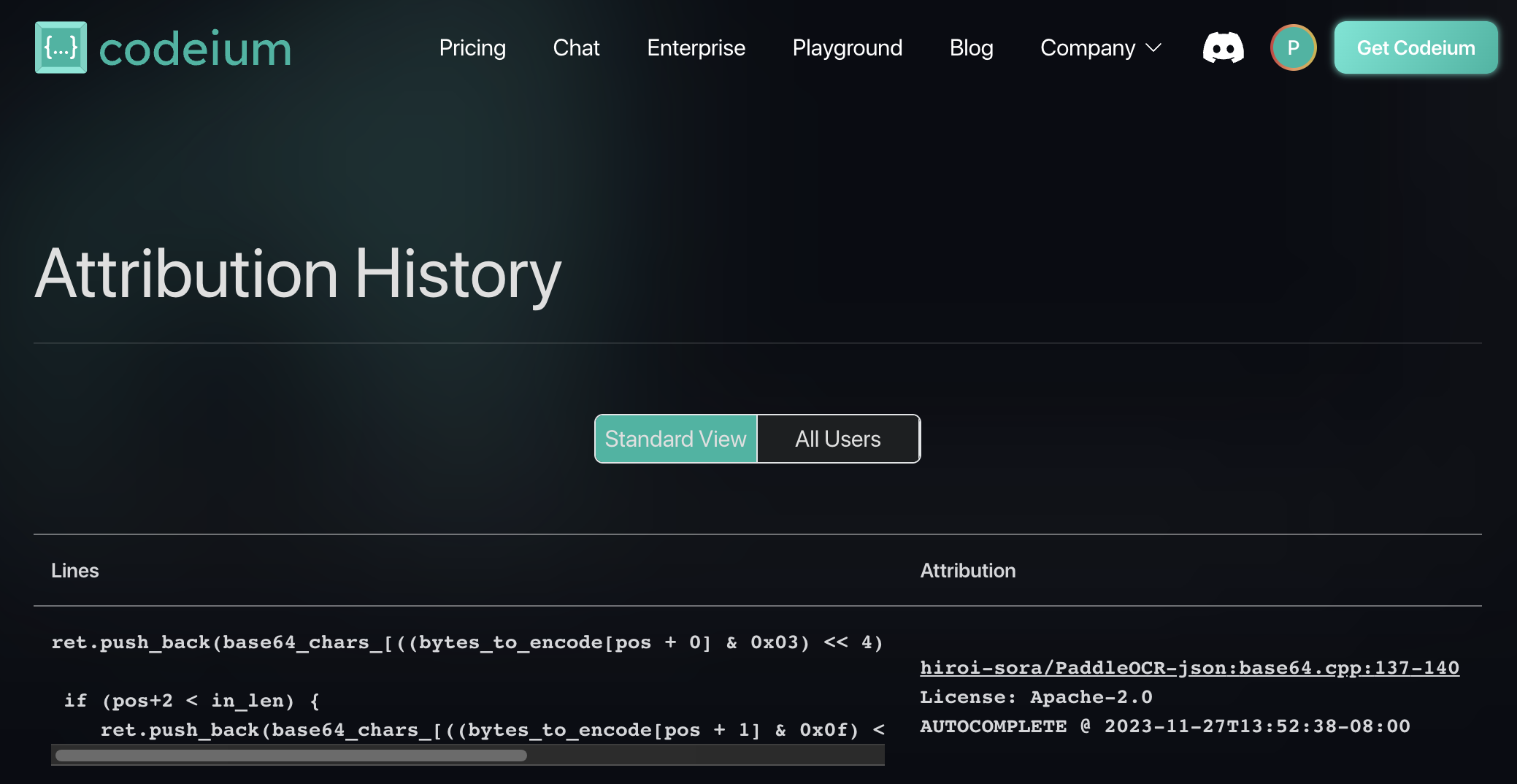
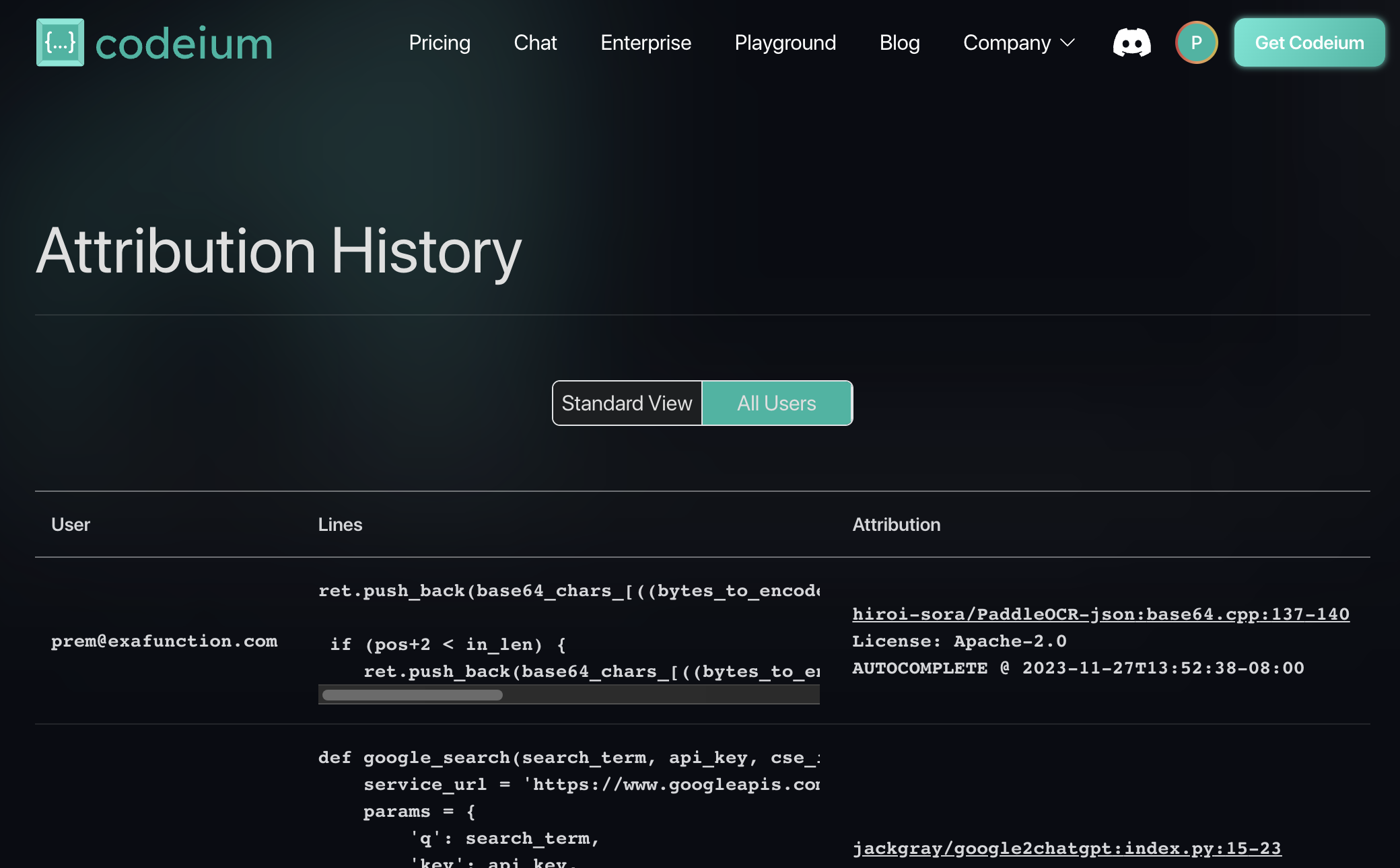
Uniquely, however, if a company desires, we can also enable an audit log for all matches on both the individual and team level.
An individual will be able to see all matches that they triggered on their profile page:
And an admin will be able to see all matches across all developers:
Moving Forwards
Today, attribution filters are available for enterprise customers, and audit logs should be discussed with a Codeium representative.
Moving forwards, we want to obviously continue to improve the precision of our matching algorithms, and investigate even more advanced matching techniques that can still run in the extremely low latency budget. Also, we recognize that some companies may have the permission or rights to use certain non-permissively licensed repositories, so we will look into enterprise-level configurability at the repository level.
If your company cares about compliance in their generative AI solutions, then contact us to chat about Codeium: