Today, we are launching our first family of models, dubbed SWE-1, optimized for the entire software engineering process, not just the task of coding.
This family is currently comprised of three distinct models:
- SWE-1: Approximately Claude 3.5 Sonnet levels of tool-call reasoning while being cheaper to serve. It will be available to all paid users for a promotional period of 0 credits per user prompt.
- SWE-1-lite: A smaller model that replaces Cascade Base at better quality. It is available for unlimited use to all users, free or paid.
- SWE-1-mini: A small, extremely fast model that powers the Windsurf Tab passive experience for all users, free or paid.
Why build SWE-1? Simply put, our goal is to accelerate software development by 99%. Writing code is only a fraction of what you do. A “coding-capable” model won’t cut it.
The Quick Background
Models that can code have gotten way better in the last couple of years. Our expectations for these models have gone from making short autocomplete suggestions to reliably building simple applications in a single shot.
But there are a couple places these models will plateau at.
First, any software developer will tell you that not all time is spent on writing code. We do more types of tasks and work on more surfaces, and so we need to expect more from models. Models that not only read and write code, but also work in the terminal, access other knowledge and the internet, test and play with your product, understand user feedback. Everything that software developers do isn’t just writing code.
Second, any software developer will tell you that work happens across all of these surfaces on a long horizon, progressing along a string of incomplete states. The best foundational models for coding today are still primarily trained on tactical work – does the final code compile and pass a unit test? But for you, a unit test is just one part of a much bigger engineering problem. There are many ways to implement a feature so that it works today – there are far fewer good ways to implement a feature that you can build upon for years. That’s why you see models do great in Cascade with active user guidance, but significantly less well the longer it operates independently. Automating more of your workflow requires removing that limitation. It requires modeling the full complexity of the engineering process: reasoning over incomplete states, with potentially ambiguous outcomes.
At some point, just getting better at coding will not make you or a model better at software engineering. And we ultimately want to help accelerate everything a software engineer can do, so we have known for quite a while that we are going to need “software engineering” models. SWE models for short.
SWE-1
Enabled from the insight from our heavily-used Windsurf Editor, we got to work building a completely new data model (the shared timeline) and a training recipe that encapsulates incomplete states, long-running tasks, and multiple surfaces.
We set out with an initial goal of proving that we can reach frontier-level performance with this approach, even with a smaller team of engineers and less compute than a research lab. SWE-1 is the initial proof of concept.
Overall, SWE-1 is close to all of the frontier foundation models. Importantly, it outperforms all non-frontier models and open-weight alternatives. For purposes of benchmarking, we ran both offline evaluation and blind production experiments.
Offline Evaluation
We compared SWE-1’s performance to the Anthropic family of models, some of the most popular by usage within Cascade, as well as leading coding open-weight models in Deepseek and Qwen.
Conversational SWE Task Benchmark: Starting in the middle of an existing Cascade session, with a half-finished task, how well does Cascade address the next user query? The 0-10 score is a blended average of judge scores for helpfulness, efficiency, and correctness, and accuracy metrics for target file edits.
This is a benchmark that we feel captures the unique nature of human-in-the-loop agentic coding that we pioneered with Cascade. As long as models are imperfect, we feel that being able to interleave seamlessly with user input on partly finished tasks is a very important measure of model usefulness.

End-To-End SWE Task Benchmark: Starting from the very beginning of a conversation, how well does Cascade address an input intent by passing a select set of unit tests? The 0-10 score is a blended average of test pass rate and judge score.
This is a benchmark to capture the ability of the model to operate independently to solve a problem end to end. This is an increasingly important use case as all models become more and more capable of operating without human intervention.
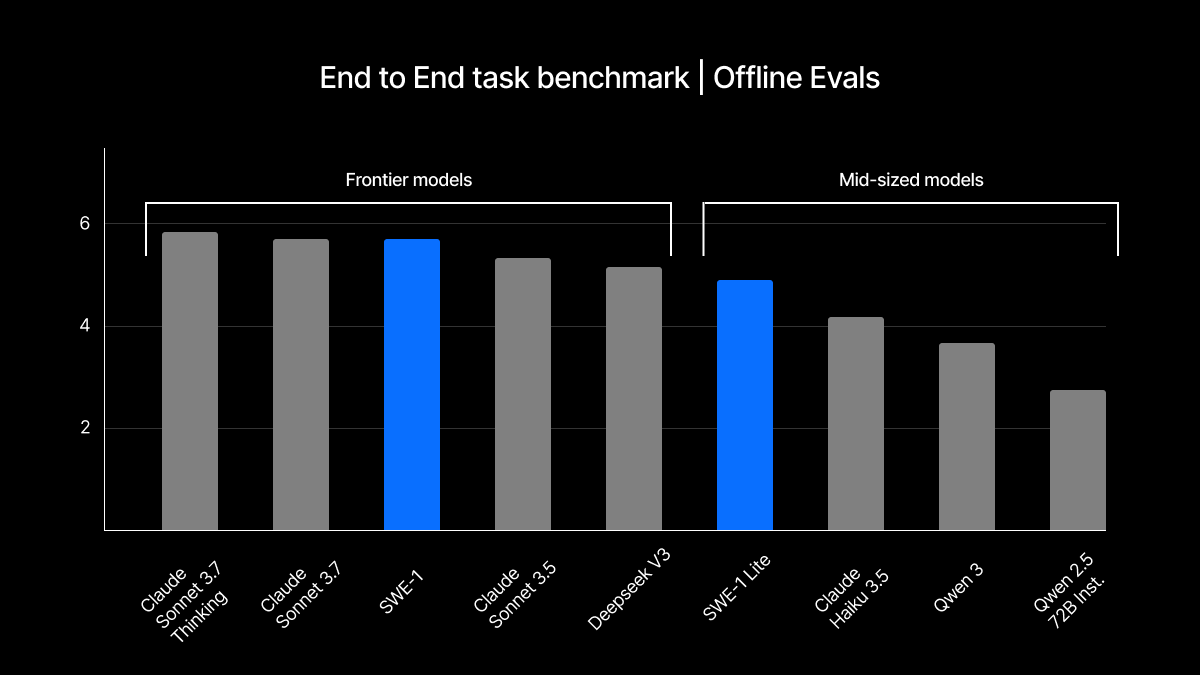
From offline evaluation, we believe that SWE-1 is within the realm of the frontier models from the foundation model labs for these tasks, and superior to mid-sized models and frontier models from the leading open-weight alternatives. It is not the absolute frontier, but shows promise to be competitive with the leading models.
Production Experiments
Because we have a large user community, we also rely on production experiments to complement the offline evaluations. To compute these daily metrics, we conducted a blind experiment with a percentage of users without knowledge of which model they were accessing. The model was held constant per user so that we could measure repeat usage over time.
We include the Claude models as benchmark because they have historically been and continue to be the most commonly used models in Cascade.
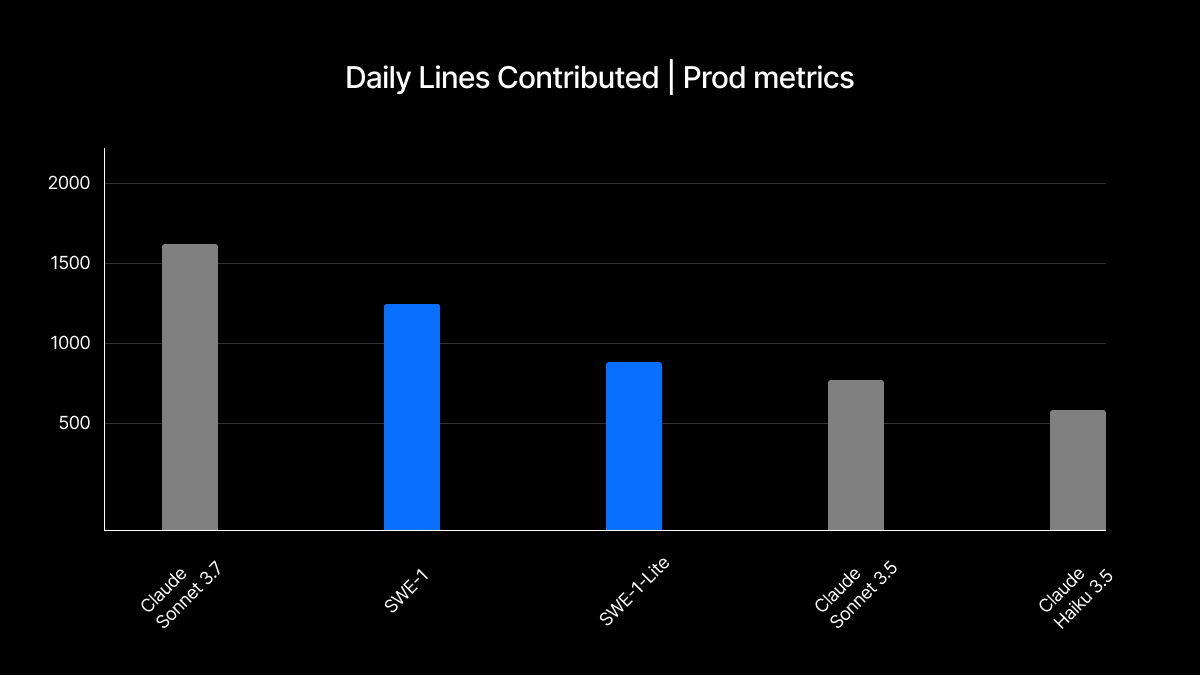
Daily Lines Contributed per User: Average number of lines written by Cascade, and actively accepted and retained by the user over a fixed time. This is a measure of overall helpfulness, reflective of both how helpful a model’s contributions are each time it is invoked as well as a user’s willingness to continue using the model repeatedly over time.
We think this is a very indicative metric that reflects a balance of proactiveness and suggestion quality, but also speed to output and responsiveness to feedback that leads users to become “repeat customers”.
Cascade Contribution Rate: For files edited at least once by Cascade, this is the percentage of changes made to those files that come from Cascade. This is a measure of helpfulness, normalized for how frequently a user wants to use that model, and how willing the model is to contribute code. Because this only measures files that the model edits, it tries to control for usage frequency and model edit propensity.
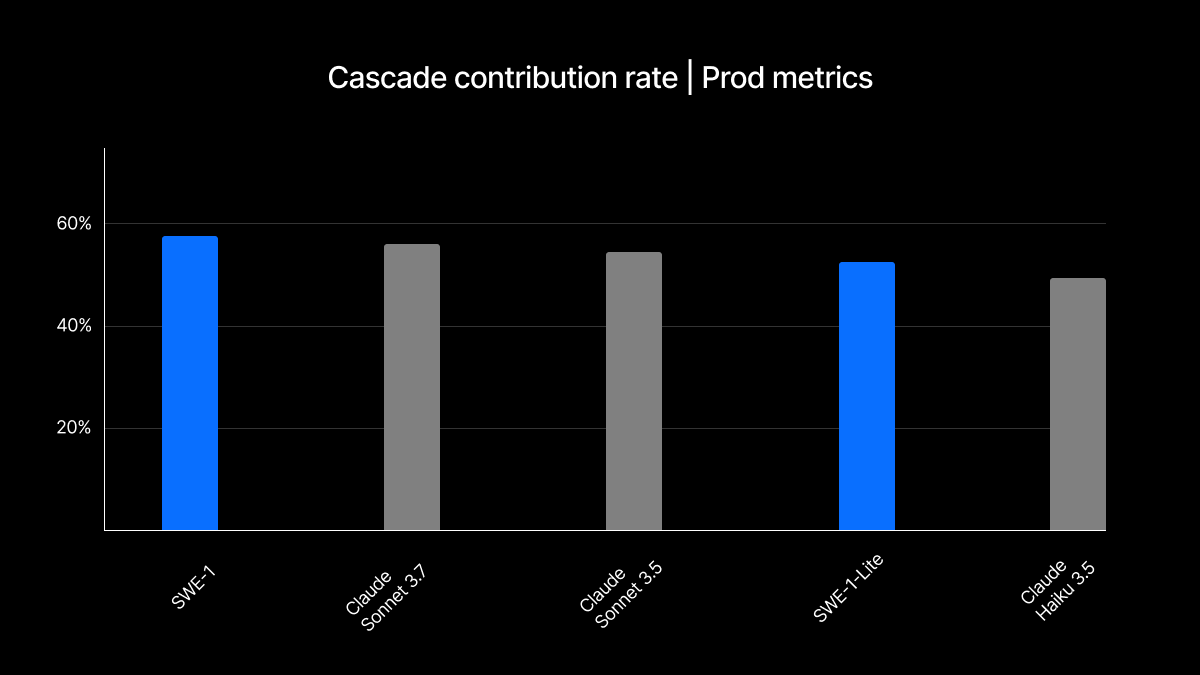
SWE-1 is built and overfit to the kinds of interactions that our users have with Cascade, so we are not very surprised that it appears to be near-industry-leading in these production experiments.
Other Models and Analysis
In the graphs and charts above, you would notice SWE-1-lite, a mid-sized version of the SWE-1 model built with the same training methodology. It is leading all of the other non-frontier, mid-sized models, and will replace our Cascade Base model as the unlimited option for all of our users.
We have also built a third model, SWE-1-mini, which shares a lot of the same training methodology around flow awareness, but small enough to run within the latency constraints of a passive predictive system and with further training for the predictive action task (as opposed to tool calling).
To be clear, this is just the beginning. In the end, within the domain of software engineering, our goal is not to match frontier model performance of any research lab, but to exceed all of them. We believe more than ever that we have the engine to do so, and we will be investing heavily in this strategy going forwards.
Our Flow-Aware System
We started the previous section with “enabled from the insight from our heavily-used Windsurf Editor.” We should explain how the Windsurf Editor enabled SWE-1, and why we are so confident our models will be the best ones when it is all said and done.
It comes down to how we can incrementally iterate: flow awareness.
What is flow awareness? We built the Windsurf Editor in order to build a seamless intertwining between the comprehensive states of user and the AI. Anything that the AI does, the human should be able to observe and action on, and anything the human does, the AI should be able to observe and action on. We call this awareness of the shared timeline “flow awareness,” and thus why we have always referred to our collaborative agentic experience as “AI flows.”
Why is an Editor that supports flow awareness critical? Simply put, it will be a while before any SWE model can truly do everything independently. Flow awareness enables the right form of interaction during this intermediate period - take whatever such a model can do, and where it makes mistakes, let the human jump in to course correct, with the model then continuing by building off what the human did. Seamless, natural switch-offs.
This means that at any given time, we at Windsurf always know the true limit of capability of the current models by looking at what steps the models complete with and without user intervention within this shared timeline. We always know, at scale, exactly what our users want us to improve with our models next. That’s how we’ve been able to rapidly build our model to the level it has achieved in today’s SWE-1 state, and that’s why we believe we’ll eventually build the absolute best SWE model.
In fact, whether you’ve noticed it or not, building the shared timeline has been the guiding vision for a number of major features to Cascade:
- At the launch of Cascade, one of the things we highlighted was that you could make some edits in the text editor and then just type “continue” in Cascade and Cascade will automatically incorporate the edits you just made. That’s awareness of the text editor.
- Soon after, we incorporated the terminal outputs into the flow awareness so that Cascade is seamlessly aware of errors you encountered while running your code. That’s awareness of the terminal.
- In Wave 4, we added the concept of Previews so that Cascade will have some understanding of the kinds of frontend components or errors that the user is interacting with and are interested in. That’s a basic awareness of the browser.
But everything in Windsurf is built on this concept of flow awareness, not just Cascade. Tab is built on this same shared timeline concept. When we add context to Cascade, we are also adding it to Tab. And it hasn’t just been arbitrarily throwing more information into a fixed context window. It has been a very careful construction of the shared timeline that best reflects the user’s actions and goals. This is why our version of Tab has:
- Awareness of your terminal commands (Wave 5)
- Awareness of what you’ve copied in your clipboard (Wave 5)
- Awareness of the current Cascade conversation (Wave 5)
- Awareness of in-IDE user searches (Wave 6)
We don’t release random features. We have been chipping away towards building the richest representation of a shared timeline of software engineering work that exists. Even while using off-the-shelf models, our tool has significantly improved from the sheer existence of the information in the shared timeline. But now with our own SWE models, we can really kick into motion this flywheel of having models that can ingest the timeline and start acting on more and more of the timeline.
What’s Next
As mentioned earlier, SWE-1 was achieved with a small but incredibly focused team, leveraging our strengths as a product and infrastructure company. It represents our first attempt to build truly frontier-quality models and while we are proud of the results, we know it is just the start. We’ve highlighted the power of our unique flywheel of applications, systems, and models, something even the foundation labs themselves would be unable to have without the kind of application surface and scale of activity-derived insight that we operate on.
You will keep on hearing about improvements to the SWE family of models moving forwards. We will invest even more in this going forward to bring our users the best performance, at simultaneously the lowest cost, so that you can keep using Windsurf to build bigger and better things.
If you want to work on this problem we are rapidly scaling our ML research and engineering teams. Apply here.