You should have your own arenas, in your own context. Most people think they know what models work best for them, but often just repeat influencers or rely on their (faulty, biased) memory or vague “vibes”. Arenas make it easy for you to KNOW for yourself from direct comparison. If you are an engineering leader, Arenas make it possible for you to make evidence-based decisions and recommendations based on direct data from your engineers, not hasty rationalization of priors.
Arenas are a very good form of online evals for models:
- They match real life use cases closer than academic benchmarks,
- They provide 1 unambiguous number with high sample size,
- They update quickly on new model launches or secret quantization,
- They never saturate.
Beyond just quantitative numbers, the exercise of engaging in side by side model evals is also highly educational because you get a feel for the qualitative “personalities”, reasoning patterns, and localized differences between models. One well known psychology/ML principle is that humans are much better at spotting the differences between two outputs than evaluating single outputs. For all these reasons and more, Chatbot Arena (now simply Arena) forever changed the game of model evaluation.
View on XI pretty much only trust two LLM evals right now: Chatbot Arena and r/LocalLlama comments section
Why a new Arena?
However, Arenas also have many known issues:
- There is often suspicion of gaming by model labs,
- They are decided by people who test on a blank slate, rather than in a “real” context with your actual code and tools,
- They simply cannot include the massive amount of context for modern agents to do their job well.
Three minor nuances also complicate interpretation of existing Arena numbers:
- Style Issues: because they are not that discerning about the output, arena participants often vote based on single turn quick tests and superficial output format proxies for quality (necessitating style control)
- Task mismatch: maybe you agree that GPT 5.2 is the best overall coding model, but you primarily work on a Java codebase. Is GPT 5.2 good at Java? Maybe you think Opus 4.5 is the best Java model, but sometimes you’re building new features with a ton of MCPs and skills, some times you’re bugfixing, sometimes you’re trying to just understand your codebase. Which model is best at which part of the development workflow? Can ONE number accurately reflect all these usages?
- Speed penalty: Throttling to the later of different response times means that fast models do not get credit for answering fast enough to either be immediately correct, or allow the human to interactively refine their prompt, rather than spend a long time up front for prompting a smart model that doesn’t allow interactivity.
- Speed of response changes the way you prompt, and the end-to-end experience/quality of a “lower Elo” fast model with human intervention is often better than a “smart” model in practice even discounting total latency. In other words, 3 short turns with a “fast” model that keeps you in flow, can be more useful/accurate than 1 long prompt with a “smart” model.
We think the world deserves more unique, personalized arenas that reflect your actual workflow, and are excited to contribute to both your personal model mastery by being the world’s first team to bring Arenas into your IDE, directly in the context of where you work.
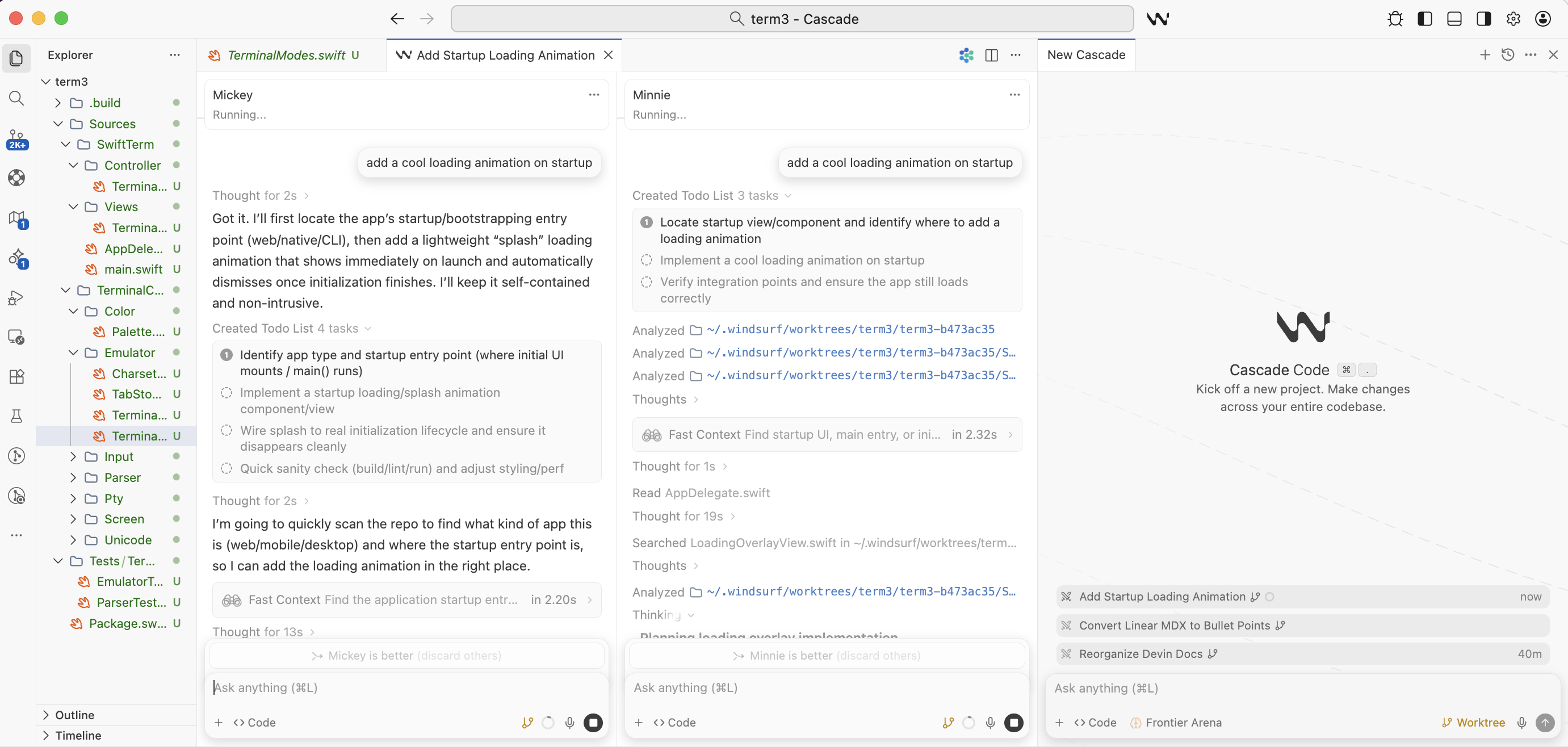
How to Arena Mode
To get started with Arena mode, download Windsurf and select the new Arena tab in the model picker:
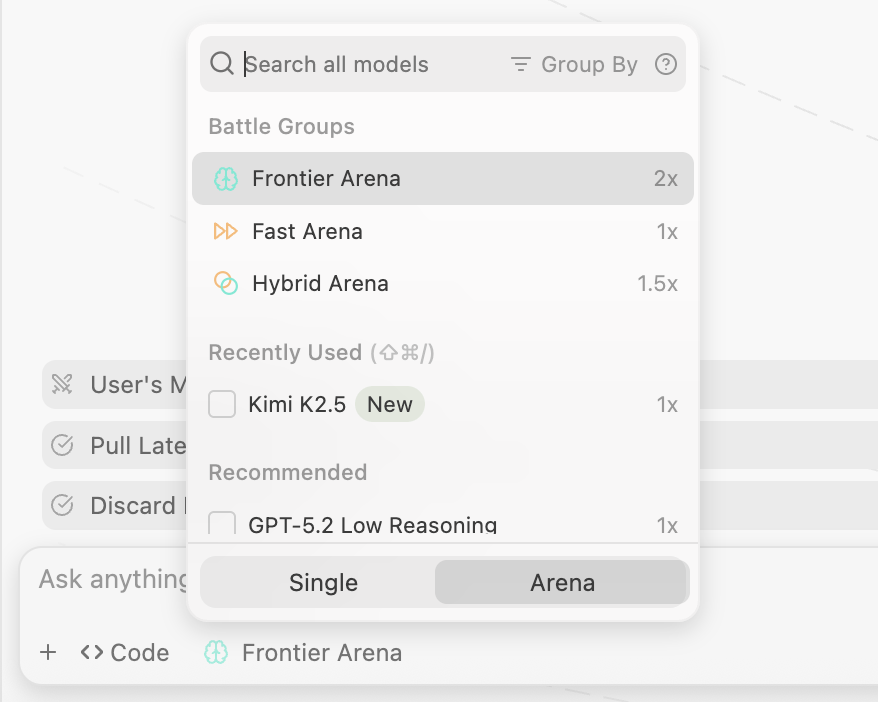
You can choose either specific models to test or allow random choice from our curated battle groups (“fast models” vs “smart models”). From here on it is a superset of the normal Cascade agent — just start typing in your prompts to the code agent normally. This will start up 2 side by side Cascade agents with hidden model names — leave them in the sidebar or drag them to the main panel, your choice.
In a world where Context Engineering is King, simply porting the standard Arena in your IDE should produce results that are FAR closer to your real life experience, because you are literally producing votes by just working in context of your day to day coding tools rather than a separate website.
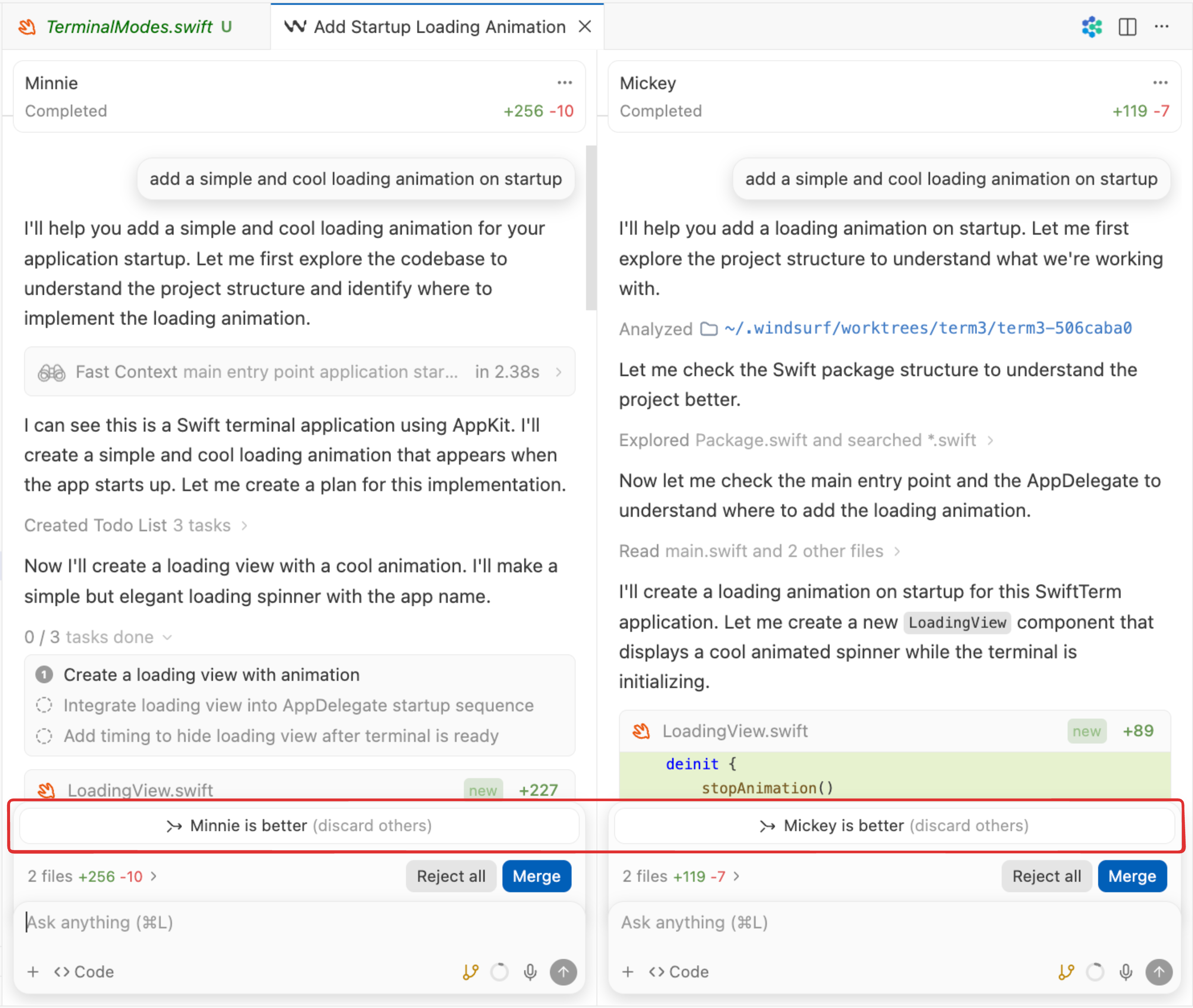
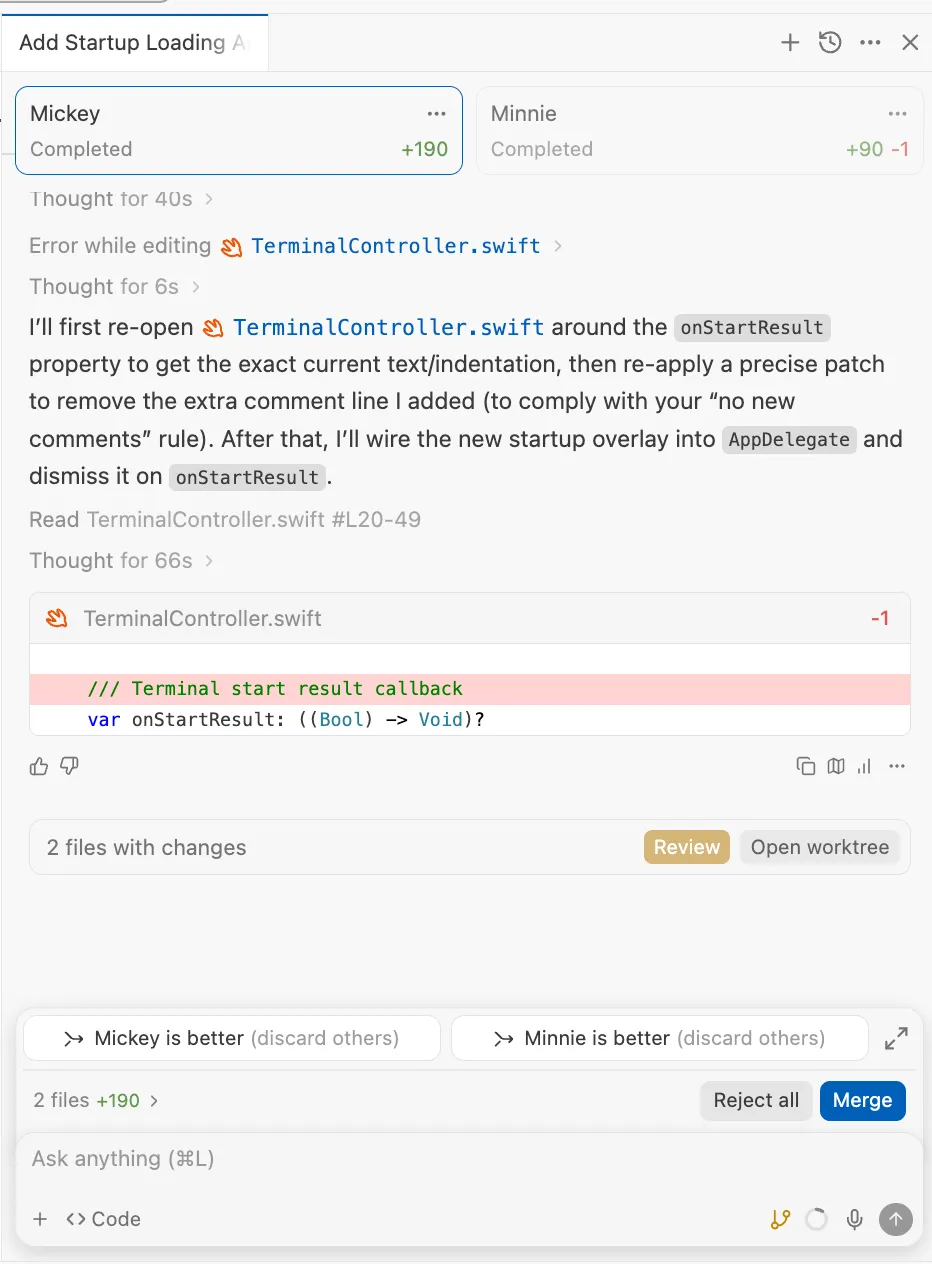
You can choose to sync followup chats to both agents at once, or branch them and take paths individually. Either way, when you have one chat trajectory that is clearly better, you can choose them at the bottom and the new Elos will be calculated. These populate both a personal leaderboard (only your votes) and a global one (across the Windsurf userbase). In future, we may offer a leaderboard for teams/enterprises above a certain size as well, and break out separate arenas for the top task categories and languages so you can use the best models for your context.
To bootstrap this leaderboard, all battle groups in Arena Mode are free for one week, after which we will release the results with more models coming online each week.
Because our goal is to make Arena mode as clear a superset of the single agent experience, we will also normalizing the price of the double runs to cost the same as a single run — a discount of roughly ~50% on inference.
But I don’t care…
…about pretty charts on a leaderboard, I am here to write code, not engage in cute science experiments
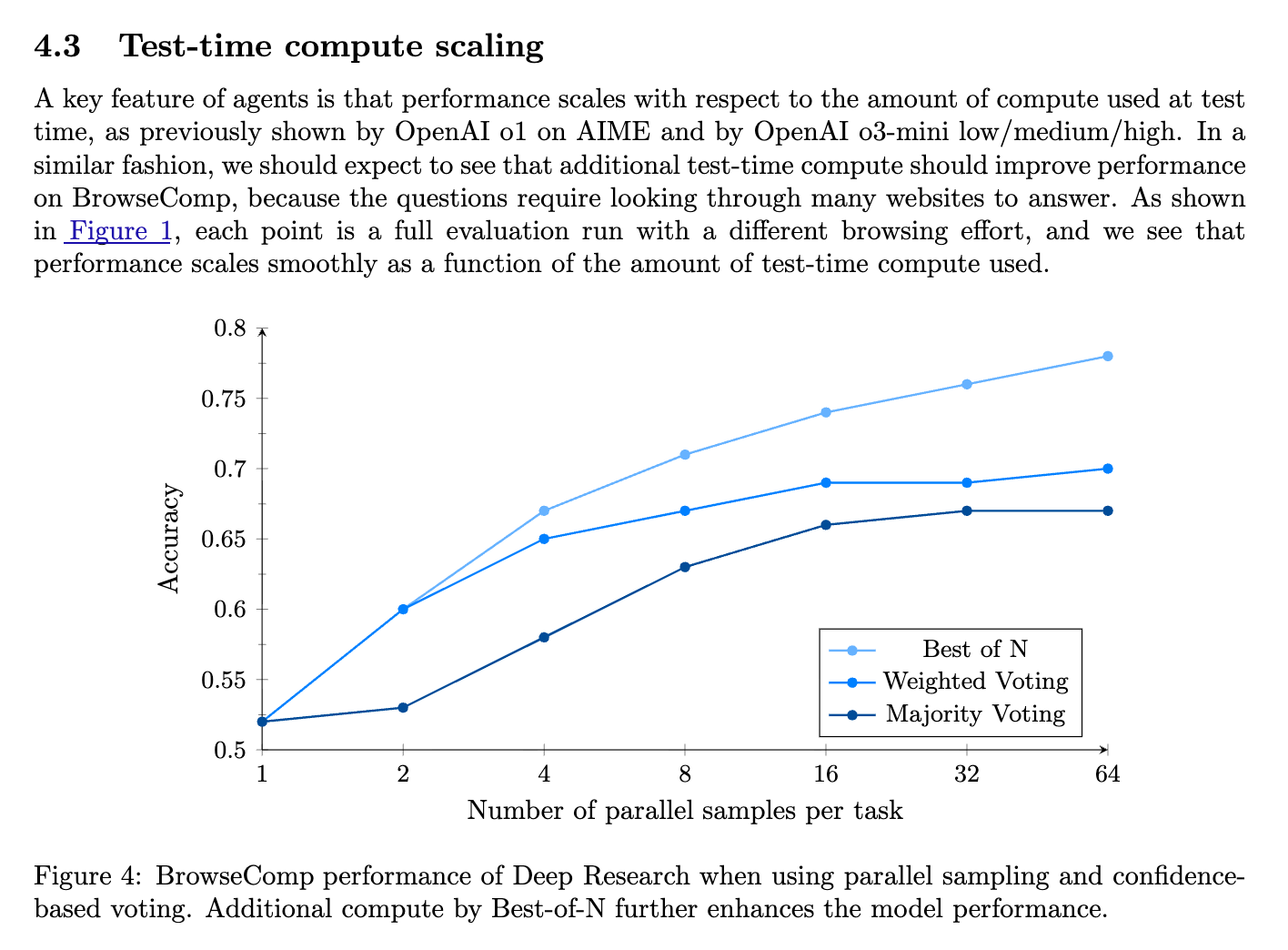
You should still care about easy access to parallel inference, because one of the most consistent results in LLM research is Self-Consistency — generating multiple responses (both from multiple LLMs but also just sampling from the same LLM multiple times) and then picking the best of, rather than relying on a single response. This is the basic intuition behind both GPT 5 Pro and Gemini 3 Deep Think, and has been both evolved and explicitly stated in system cards where the uplift of Best-of-N can be over 20 percentage points on a Deep Research task:
While you can use an LLM to judge between the responses, there are some well documented biases to those LLMs as judge, and of course you are much more likely to be a better judge of the parallel results than any LLM anyway.
In this context, your role as a software engineer evolves more clearly away from writing code to starting a task and letting multiple models compete to do your job best, while you serve as code reviewer/engineering manager.
Using Arena Mode in this way gives you a hint at our possible next steps with the future of Windsurf…
Plan Mode
As part of Wave 14, we’ve also added Plan Mode to Windsurf. You can switch to Plan Mode using the same Cascade toggle for Code and Ask Mode.
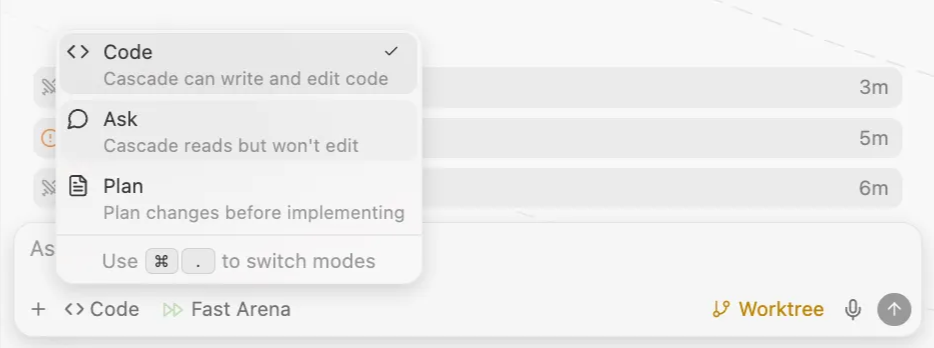
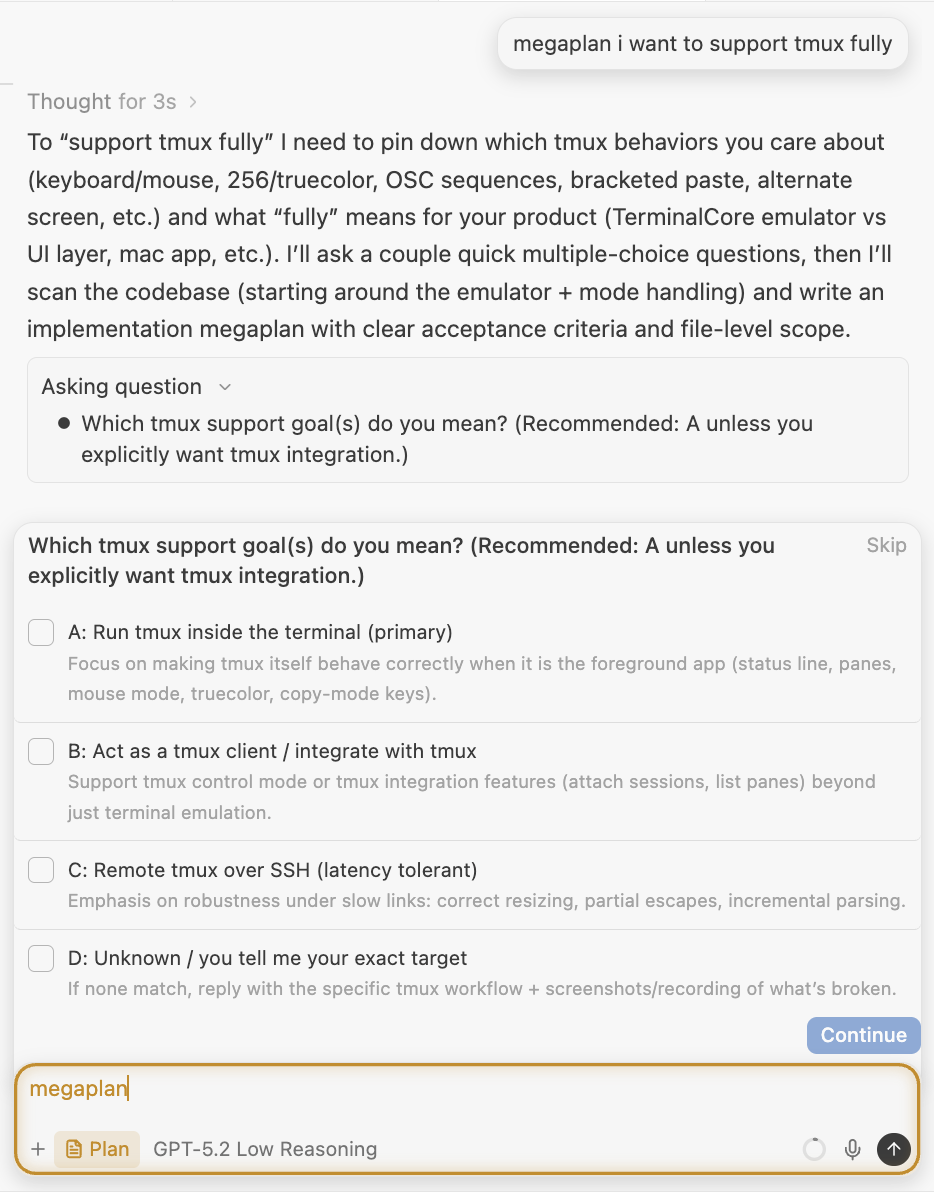
Pro tip: type “megaplan” in the Cascade input box to trigger an advanced form of Plan Mode that asks you more questions to create a more aligned plan.