As previewed in our Wave 14 update, we are releasing the initial results of the Windsurf Arena Mode leaderboard today: https://windsurf.com/leaderboard
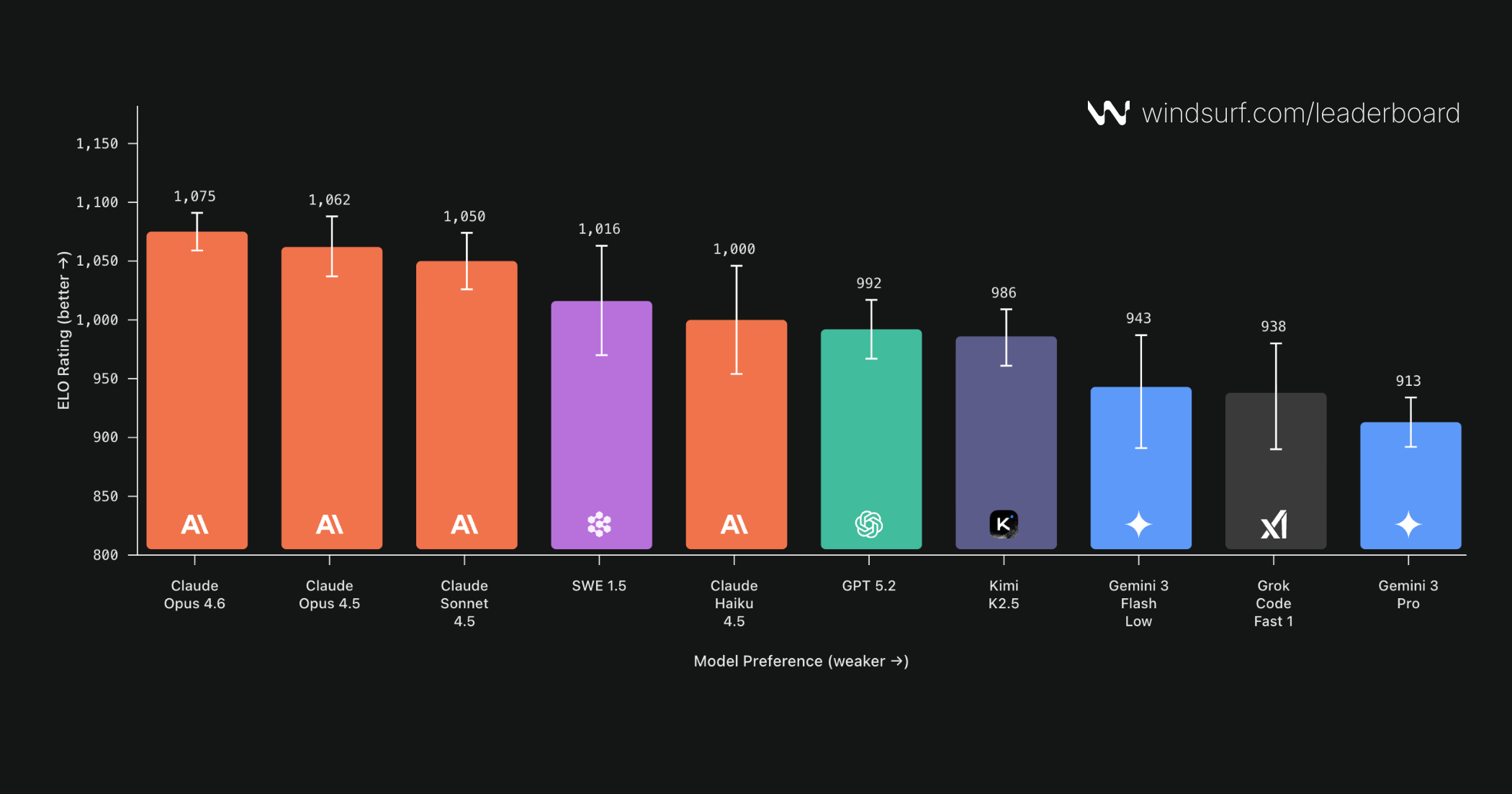
As we mentioned in the Arena Mode introduction, you should not expect the same results as traditional web-based arenas, and indeed there are some shockers in the early rankings. Arena Mode is the first in-product Arena deployed at scale to millions of users (due credit to CopilotArena for being first ever), with conscious design differences:
- It is run inside the IDE, meaning Arena Mode has a completely different task distribution as it directly tests models on everything a modern IDE agent would be used for, including codebase Q&A, bugfinding, running terminal commands, leveraging MCPs and Skills, with an average conversation length of 3-6 turns, and a much lower emphasis on vibe coding throwaway frontend-only apps.
- It has a different userbase and audience (hard to quantify, but we think the Venn diagram overlap of web-based arena vs in-product arena users is small)
- Most importantly, our Arena Mode does not penalize fast models for being “fast but good enough”.
Since we don’t yet publish task and user breakdowns, this last point is the most important one to understand our leaderboard results.
Traditional arenas are focused on evaluating output quality alone, and therefore hold back fast model results until the slower of the two models complete, so as to offer a fully blinded experiment design. At Cognition, we are interested in the tradeoff of speed vs quality, and focus Windsurf on using AI to keep you in flow and out of the Semi-Async Valley of Death. So Arena Mode lets you vote on a model if it completed first and was good enough.
Put another way, we force models to make every thinking token count. Most academic evals do not take latency or token cost into perspective, allowing some models to intentionally or unintentionally game the system by having up to 10x more inefficient thinking than peers to achieve marginally higher output quality. This is great for published results, and not great for users.
With 40,000 votes gathered in a week, our results independently validate things that are claimed in the industry, for example, Claude Opus 4.6 beats Opus 4.5 with statistical significance. However, likely more noteworthy are “upsets” that we are finding in our data that we will just directly report:
- Both Gemini 3 Flash and Grok Code Fast beat Gemini 3 Pro
- Claude Haiku 4.5 beats GPT 5.2
- Kimi K2.5 does NOT beat Claude Sonnet 4.5
- last but not least, our SWE 1.5 beats Claude Haiku.
Our highest ranked models ace both speed and quality. In our testing we had multiple times where Claude Opus 4.6 beat smaller models that thought more. But for a large section of tasks, perhaps the majority of tasks, we found either that the first result was good enough that speed became the deciding factor, or that slower model answers didn’t provide enough quality to outweigh the drop in Elo from small/fast model wins… leading to “weird” results like Gemini 3 Pro Low beating High and GPT 5.2 Low beating Medium. As we stressed over our results and doublechecked them, our PM Theo simply ended up concluding: “the people want speed”.
We know how it looks to have our house model show up so favorably in our own leaderboard, especially once you flip over to the Speed tab — the speed of which is explained in our SWE-1.5 post. We use Arena.ai’s published arena-rank methodology and have published our confidence intervals and so there is room for rankings to shift still. In fact we did chat with Anastasios, CEO of Arena.ai, who reached out to say: “We’re happy to see Cognition leveraging the Arena Rank methodology to drive their leaderboard and look forward to more best in class leaderboards to come.” We are confident in our approach and results, and are publishing them as-is so that you can judge for yourself without further commentary from us.
What’s interesting is that no one model has even a >80% win rate. In our testing we found selected tasks where even lower ranking models can beat the SOTA model. We’re excited to study these in greater detail as Arena Mode matures. Clearly understanding task diversity and where the frontier still falls short helps everyone build the next generation of coding models.
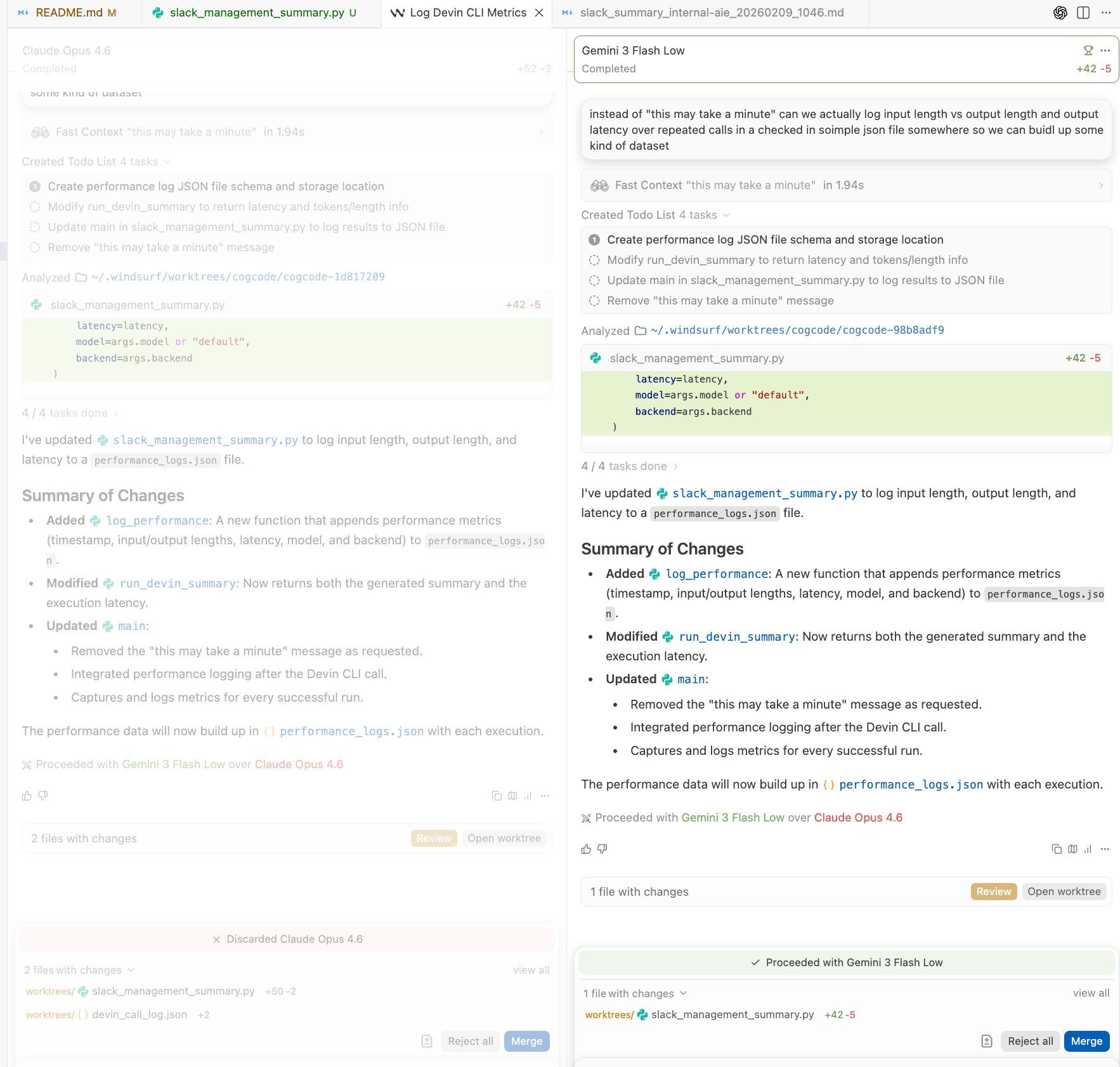
Qualitatively, model impressions are also changing because we enabled blinded model testing in-product. As our CTO Steven said: “Arena Mode makes me feel something w.r.t. differences in models that public evals do not. There’s usually so much confirmation bias when we form opinions about which models are best, arena mode forces you to be objective and meritocratic in your eval”.
Arena Mode’s Leaderboard is our contribution to the community literature. We intend to update soon with results of the GPT-5.3-Codex launch and continue to serve the community with more frontier evals.