We’re launching multiple updates to Windsurf today: an Adaptive model router, a redesigned model picker with pricing context, and the removal of daily limits for Max.
We’ve heard clear feedback that our new pricing plans were too opaque and, in some cases, too restrictive. With this update, we’re aiming to address that directly by giving users better visibility into model costs and making it easier to manage your quota.
Introducing our Adaptive model router
We’re rolling out an adaptive model router. Adaptive is designed to intelligently select the best models for your tasks. By automatically choosing the right model for each task and avoiding overuse of premium models, Adaptive will help you make your quota last longer.
You can use our new model router by choosing Adaptive in the model picker.
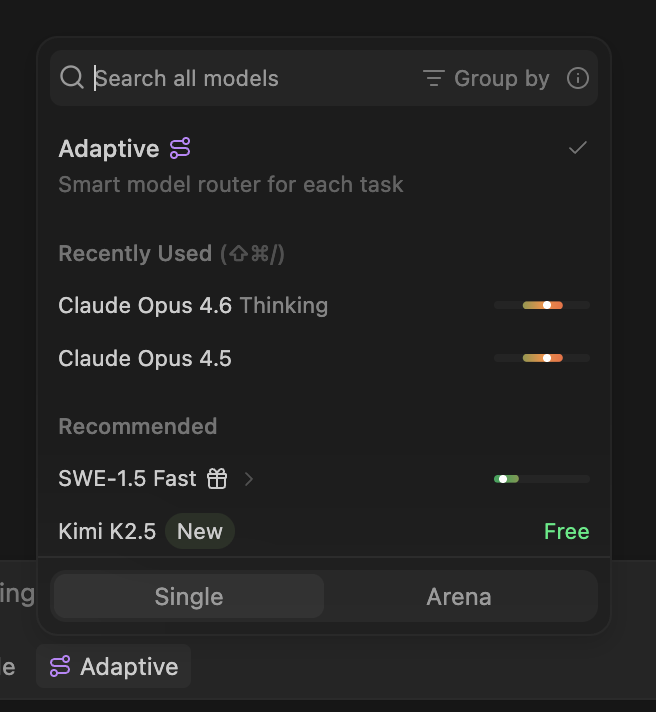
When you choose the adaptive model, we will dynamically choose the right underlying model for your task—while drawing down your quota at a fixed per-token rate. To start, we are including generous resource limits with your quota and offering extra usage beyond your quota at USD 0.50 per 1M input tokens, USD 2.00 per 1M output tokens, and USD 0.10 per 1M cache read tokens for the next 2 weeks.
We’re rolling out the Adaptive model to all self-serve users today, including Pro, Max, and Teams. We expect this to be the best default option for most users who want to stay within the quota limits throughout the month, and we’ll continue deploying new updates to improve routing performance.
Updated model picker with pricing context
When we announced new pricing, we should have been clearer that your quota and extra usage will be billed based on how many tokens your requests consume. To address that, we’re introducing a new model picker design that shows token pricing information directly, which is the exact rate extra usage is billed at.
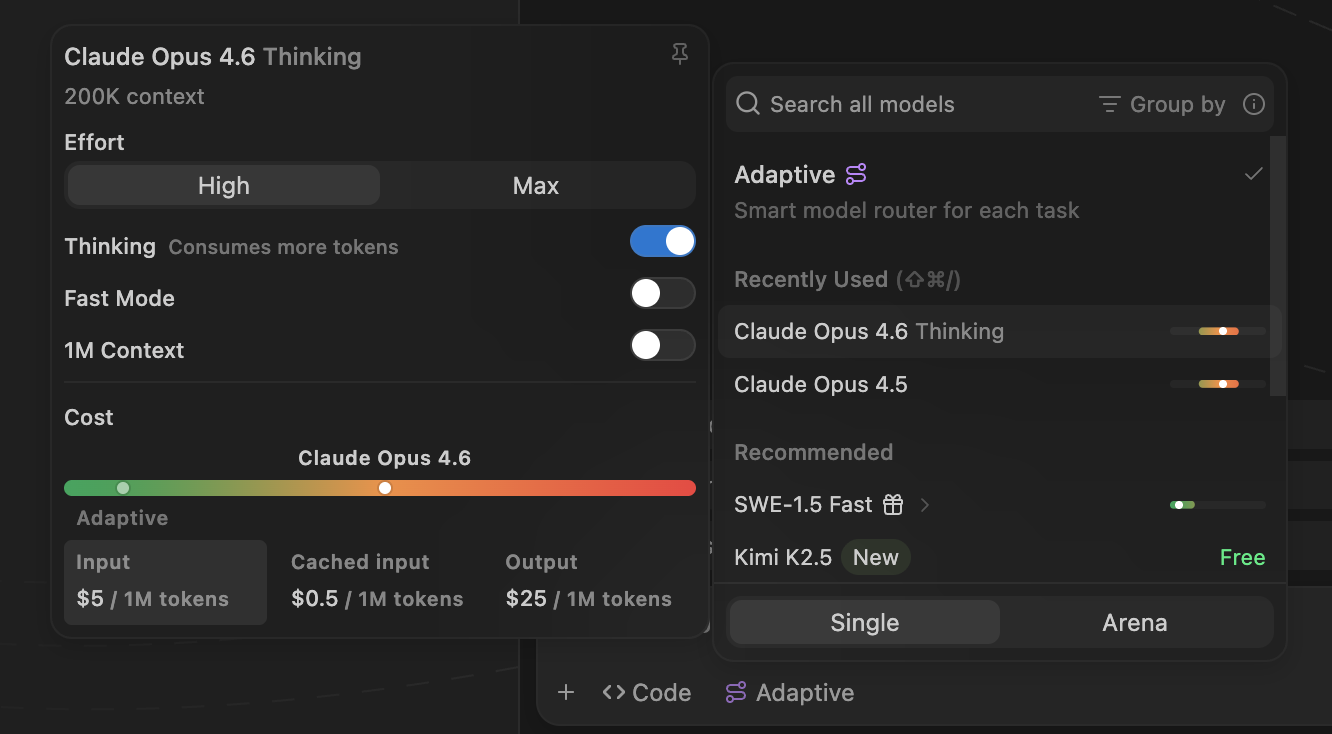
As you’ll notice from the new model picker design, prompt caching is a critical component to request costs. To make this more obvious, we’ve integrated a prompt cache timer directly into the context window indicator so you can track it more closely.
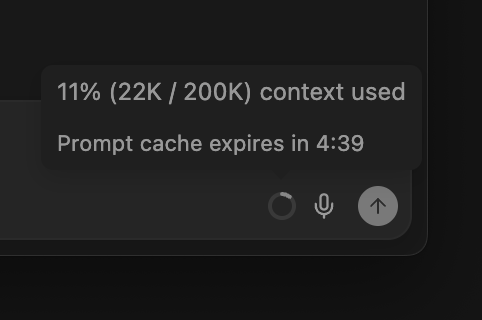
Finally, we have updated the response cards after messages to include token counts so you can understand exactly how the message cost was calculated.
No more daily limits for Max users
While the average user hasn’t been heavily impacted by the new quotas, we should have been clearer that for the heaviest users—who learned to squeeze the most out of each prompt—the new token-based pricing is a significant change.
The new Max plan is designed for power users who want to drive AI to its fullest, but we’ve heard your feedback that the daily limits felt too restrictive for bursty work.
Therefore, starting today, Max users will no longer have a daily quota. Your weekly limit remains, but you’re free to use it however your workflow demands.
We also considered removing the daily limits for all plans, but after analyzing the data decided it’s too easy to exhaust an entire week’s quota before you get a hang of prompt caching and model selection. The daily quota gives you a safety net to continue for free the next day—if you want to continue coding immediately once your quota is exhausted, you can always purchase extra usage or upgrade to Max.
What we’re working on next
Between Adaptive, the updated model picker, and the removal of daily limits for Max, we think this is a meaningful step toward a more flexible and transparent Windsurf. All updates are live today: download the latest version of Windsurf to try them out.
But we’re not stopping there: we want to continue to improve performance and efficiency for all Windsurf users. That’s why we’re working on a new, more efficient harness that will intelligently incorporate a multi-model architecture and subagents to deliver higher quality outputs at a lower overall cost. We plan to share more soon about this.