Most of the work we ask coding agents to do is local: fix a bug, add an endpoint, refactor a module. The relevant code lives in a handful of files, and an agent with a shell, grep, and read is exactly right for the job. It explores, follows references, and completes the task.
A different class of work requires reasoning over the entire codebase. Security scanning, code-quality enforcement, breaking-change detection, and more. Here, completeness is the goal.
These tasks share a defining property: the result is only trustworthy if the entire codebase was considered.
And the local-task toolkit doesn’t transfer cleanly. Point a single search-driven agent at a 50k-file repo, and ask it to remediate every instance of a problem, and three things go wrong.
- The agent spends most of its budget finding the work rather than doing it. The agent greps, opens the wrong files, backtracks, and re-decides what to inspect next. On a large repo, selection can dominate analysis.
- Context becomes a shared bottleneck. A long-running agent carries discoveries from one part of the repo while reasoning about the next. As the run grows, unrelated evidence competes for attention and context budget.
- No explicit coverage boundary. A search-driven agent stops when it decides it’s done - not when a finite work queue has been exhausted.
Share of a coding agent’s trajectory spent exploring the repository
GPT-5.4-high with Mini-SWE-Agent · 300 SWE-bench Multilingual trajectories
Zhang et al. analyzed 300 coding-agent runs and found that reading and searching consumed more than half of all tool-use turns and nearly half of the main agent’s tokens. The study classifies both activities as repository exploration; it does not claim that every read was unnecessary.
Source: Zhang et al., FastContext (2026)
Agent reliability falls as context grows
LOCA-bench · fixed task semantics · ReAct scaffold · 75 runs per context length
Environment description length
Zeng et al. held task semantics fixed while increasing the amount of information agents had to navigate. From 8K to 128K tokens, success fell from 96.0% to 34.0% for Claude Opus 4.5, 72.0% to 38.7% for GPT-5.2 Medium, and 64.0% to 21.3% for Gemini 3 Flash.
Search agents terminate while constraints remain unresolved
215 multi-constraint search tasks · up to 100 turns per task
Ko et al. evaluated search agents on questions requiring at least three independent constraints. Even the strongest trained system terminated with an underverified answer on 52.1% of tasks; an answer was underverified when at least one constraint remained unresolved or violated.
Source: Ko et al., When Is Enough Not Enough? Illusory Completion in Search Agents (2026)
These issues scale with the size of the repo. Thus, whole-codebase tasks need a different shape. We borrowed a two-decade-old idea from distributed systems - MapReduce, and adapted it for agents.
First, an agent synthesizes a deterministic relevance test. That test runs over every source file and produces a finite set of candidates. The candidates are then divided into bounded batches, investigated in parallel, and reduced into a single result.
Coverage is guaranteed by construction: the deterministic pass produces a finite work queue, every shard is assigned to an investigation agent, and the scan is complete only when that queue is exhausted.
This structure also keeps the cost down. No single agent searches the entire repo while carrying an ever-growing record of unrelated discoveries. Each worker reasons from a focused context for one bounded shard.
The Architecture
MapReduce scaled computation across a cluster: shard a large input, run the map over every shard in parallel, then reduce the results into one answer.
Agentic MapReduce scales agent reasoning the same way, with one inversion. Where classic MapReduce processes the entire input using handwritten instructions, here an agent decides what matters for the current codebase given the task. Then, a deterministic pass finds every instance of it.
| Stage | What happens | Agentic? |
|---|---|---|
| Plan | An agent studies the repo and authors selectors, patterns that identify which code is relevant | Yes |
| Shard | The selector runs deterministically over the entire repo; matches are bucketed into bounded batches | No |
| Map | One agent per batch, in parallel, does the real per-shard reasoning | Yes |
| Reduce | An agent groups, dedupes, and synthesizes the per-shard outputs into a final answer | Yes |
The principle: put agents where reasoning is required - synthesizing the decomposition function, inspecting the shards, and the reduction. Everything else is deterministic.
The Planner
The planner studies the repo and produces selectors: relevance tests concrete enough to run deterministically over the whole codebase, with no model in the loop. Reasoning is spent once, when the selectors are authored.
A selector’s language depends on the task and the codebase. It might be a Tree-sitter query over syntax nodes, a compiler query over symbols and types, a traversal of an import or call graph, a comparison of generated API schemas, or a lexical pattern for a repository-specific convention.
| Task | Example Selectors |
|---|---|
| Security Scanning | Select route declarations, auth boundaries, deserialization entry points, and calls to dangerous APIs |
| Breaking-Change Detection | Compare exported symbols or generated API schemas, then select affected consumers |
| Code-Quality Enforcement | Query syntax trees for deprecated APIs or project-specific anti-patterns |
| Large-Scale Migration | Traverse imports and references to find every caller of the interface being replaced |
Once authored, the selectors run deterministically against the codebase. Each match emits a signal: a compact record of where the match occurred, which selector produced it, and what evidence triggered it. Files that emit no signals are no longer considered as candidates for analysis. They never reach the expensive Map stage. Signals from matching files are grouped into bounded batches, and the Devin orchestrator assigns each batch to a fresh child worker session for analysis. Selectors are also persisted so they can be reused for future runs.
Completeness now rests on selector recall: a file that matches no selector never reaches a worker. We take this trade deliberately. The selectors are an inspectable, version-controlled artifact. You can read them, test them against known examples, and tune their recall to the task at hand, whereas a search agent’s “I’ve looked everywhere” is unfalsifiable.
Map and Reduce
Each Map worker is a child Devin session that kicks off with focused context - one bounded shard and the provenance that came with it - which selector fired, and on what evidence. It investigates every candidate in the shard, reading whatever surrounding code it needs to reach a verdict, and emits a structured result: zero or more findings. Workers run independently and in parallel.
After workers have finished, a Reducer session aggregates the results, only considering outputs from workers that produced findings. Workers with zero findings are ignored. The Reducer consumes the structured outputs, deduplicates overlapping results, reconciles local conclusions, and applies global prioritization to produce one coherent result. It reasons over the workers’ compressed conclusions rather than replaying their full contexts or re-reading the entire codebase.
Depending on the global task the Reducer can also identify relationships that cross shard boundaries. For a security scan, it can examine whether several identified exploits across shards can be chained together for a more severe attack path. In breaking-change detection task, it can group affected call sites from many shards under the API change that caused them and produce one migration plan.
Recall the failure mode of a traditional agentic process for this category of work: a search-driven agent spends most of its budget finding the work. Agentic MapReduce moves selection into a deterministic pass. Tokens are then spent only on the candidates that survive the selectors, and only on one bounded shard at a time. So cost tracks the amount of relevant code, and not the size of the repo the agent had to wade through to find it. The Reducer compounds the saving by reasoning over compressed conclusions rather than full transcripts.
Additionally, as a codebase evolves, re-runs of Agentic MapReduce remain cheap. The entire pipeline runs only on files that changed since the last commit scanned, so you pay for the diff and not a full pass.
Security Swarm
Devin Security Swarm is powered by Agentic MapReduce. Security scanning is the task the pattern was built for: a vulnerability report is only trustworthy if the entire codebase was considered, real bugs are sparse relative to the code that hides them, and the most severe ones chain exploits across multiple files. That shape maps exactly onto Agentic MapReduce: deterministic selection for whole-repo coverage, parallel focused investigation for depth, and a reasoning reduce step to connect findings the isolated workers couldn’t see.
A scan runs as five stages:
Plan: the threat model. A Devin session studies the repository and writes the rules for this codebase: patterns for its routes, data layer, auth wrappers, and deserialization sinks. Swarm surfaces these as an editable threat model. You can read every rule, and on an interactive scan, adjust it before the swarm fans out.
Shard: signals and batches. The rules run deterministically over the entire repo. Every match emits a signal; files that match nothing are dropped from consideration; the rest are bucketed into bounded batches.
Map: the swarm. One child Devin session per batch, in parallel, each from a fresh, focused context: its batch’s signals and the rule provenance behind them. A worker reads the real code, clears a false-positive gate, and reports findings with severity, confidence, and preconditions, accounting for every file it was handed.
Reduce: triage and chains. A reducer session consumes the workers’ findings; that is, processing their conclusions, not their transcripts; deduplicates them, attributes ownership, and triages each into P0/P1/P2. With the global view no single worker had, it composes attack chains across shards: an unauthenticated ID leak plus an ID-gated RCE become one P0 unauthenticated RCE.
Verify: runtime proof. The orchestrator Devin session fans out once more; this time over findings. One sandboxed session per serious finding reproduces it against a running build and records it as Confirmed, False Positive, or Inconclusive, so the report reflects what was actually executed. Confirmed findings can be handed back to Devin to fix, opening a remediation PR.
Agentic MapReduce Pipeline
security scan example1. Plan
AgenticFor this scan, the agent writes rules tuned to the repo — its routes, auth wrappers, and deserialization sinks.
Results
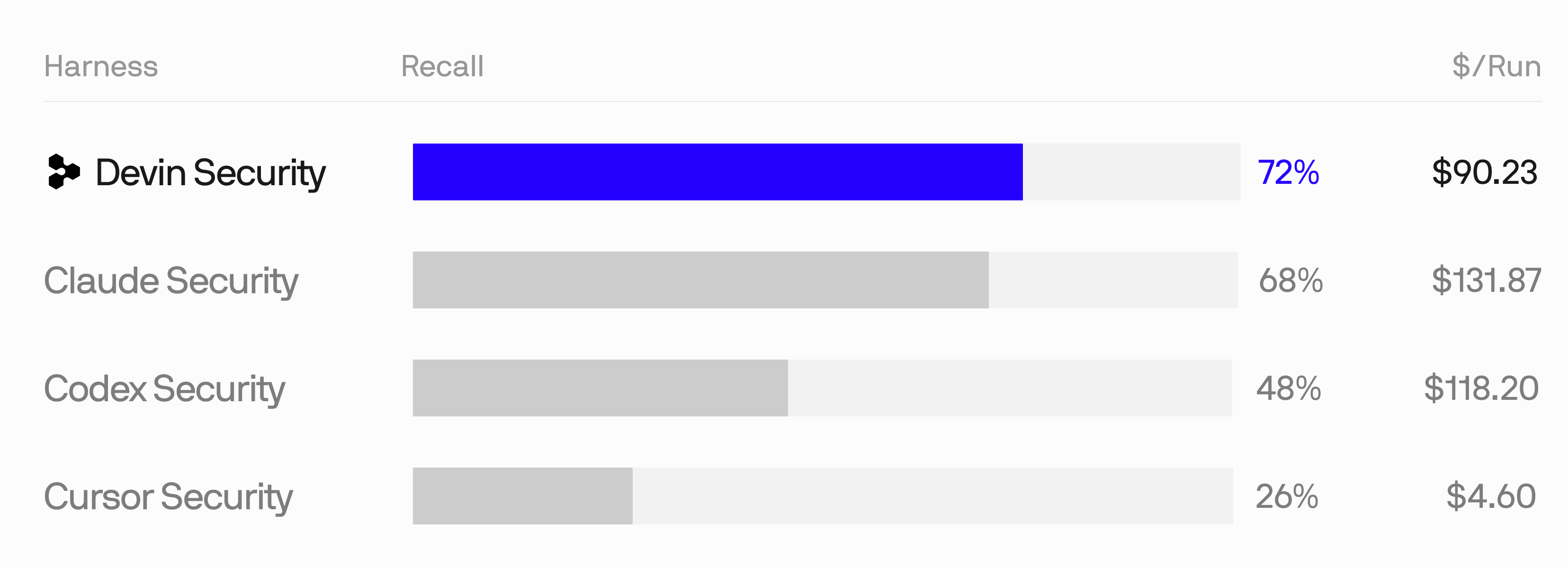
We benchmarked Security Swarm against a ground-truth set of real, published vulnerabilities. These are CVEs from the GitHub Advisory Database, each pinned to the exact commit before its fix landed, so the bug is provably present in the code we scan. The set spans dozens of cases across more than a dozen languages and vulnerability classes: RCE, SSRF, path traversal, auth bypass, unsafe deserialization, decompression-bomb DoS, and more.
We run Swarm and the other security scanners against the same pinned repositories and grade for recall: a scanner gets credit only if it surfaces a finding identifying the same underlying vulnerability, finding the same root cause and code area. Unrelated extra findings count neither for nor against it.
Devin Security Swarm sits at the top with 72% recall at a fraction of the cost of the alternatives. We go deeper on how we built this eval — and why it’s hard to game — in Evaluating Security Swarm.
Conclusion
MapReduce made it affordable to process an entire dataset at cluster scale. Agentic MapReduce does the same for reasoning: it lets an agent weigh in on every relevant line of a codebase without paying to wade through the rest. Security scanning is the first place we’ve pointed it, but the pattern fits any task where a verdict is only trustworthy if the whole codebase was in view. We think that’s a large and underserved class of work, and we’re just starting to map it.