Devinのご紹介 AIソフトウェア
 WEBAPP
WEBAPP  IDE
IDE  CLI
CLI
AIソフトウェア
エンジニア Devin
すべてのエンジニアが利用できる、バージョンアップした
WEBAPP IDE CLI 
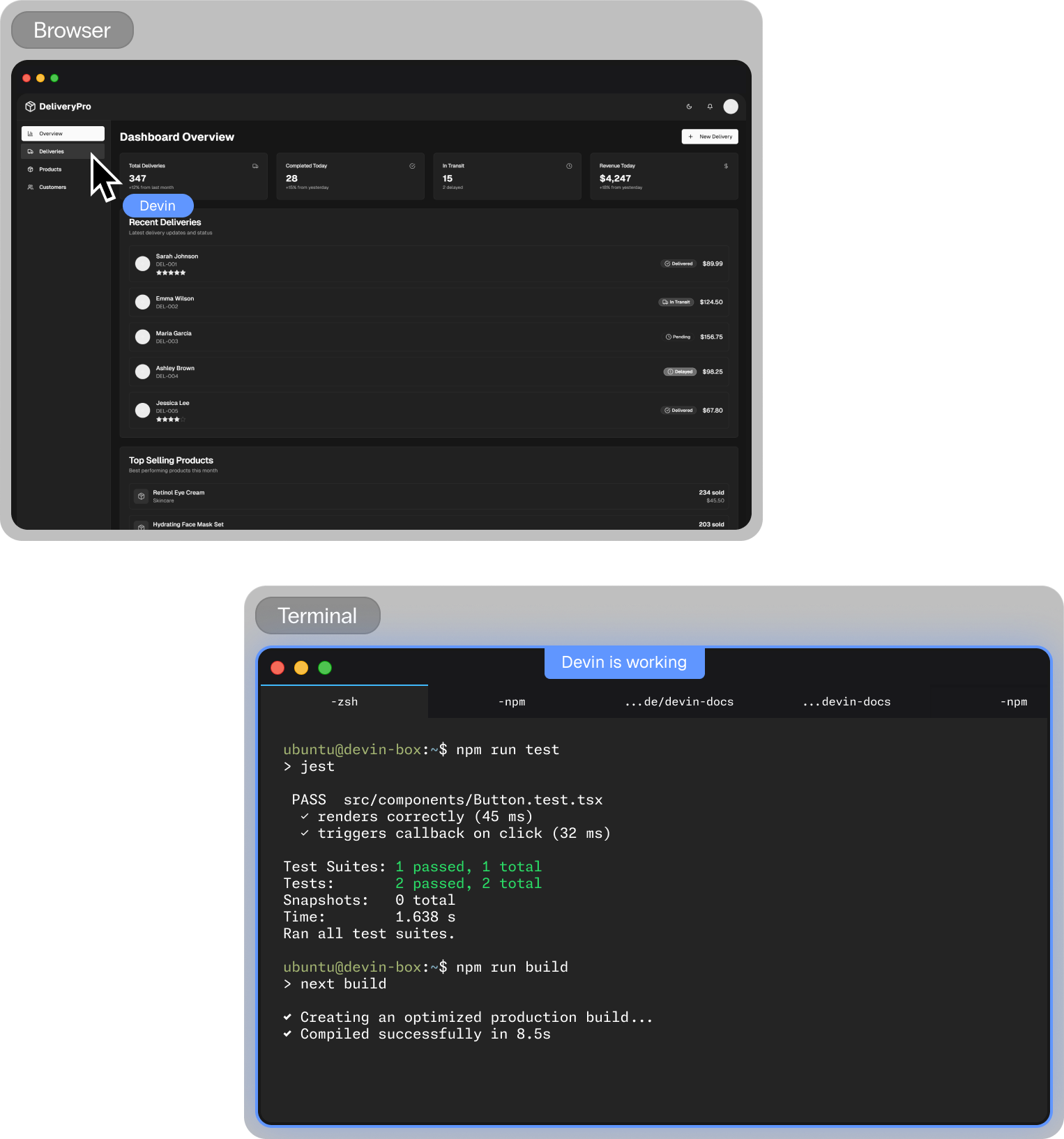
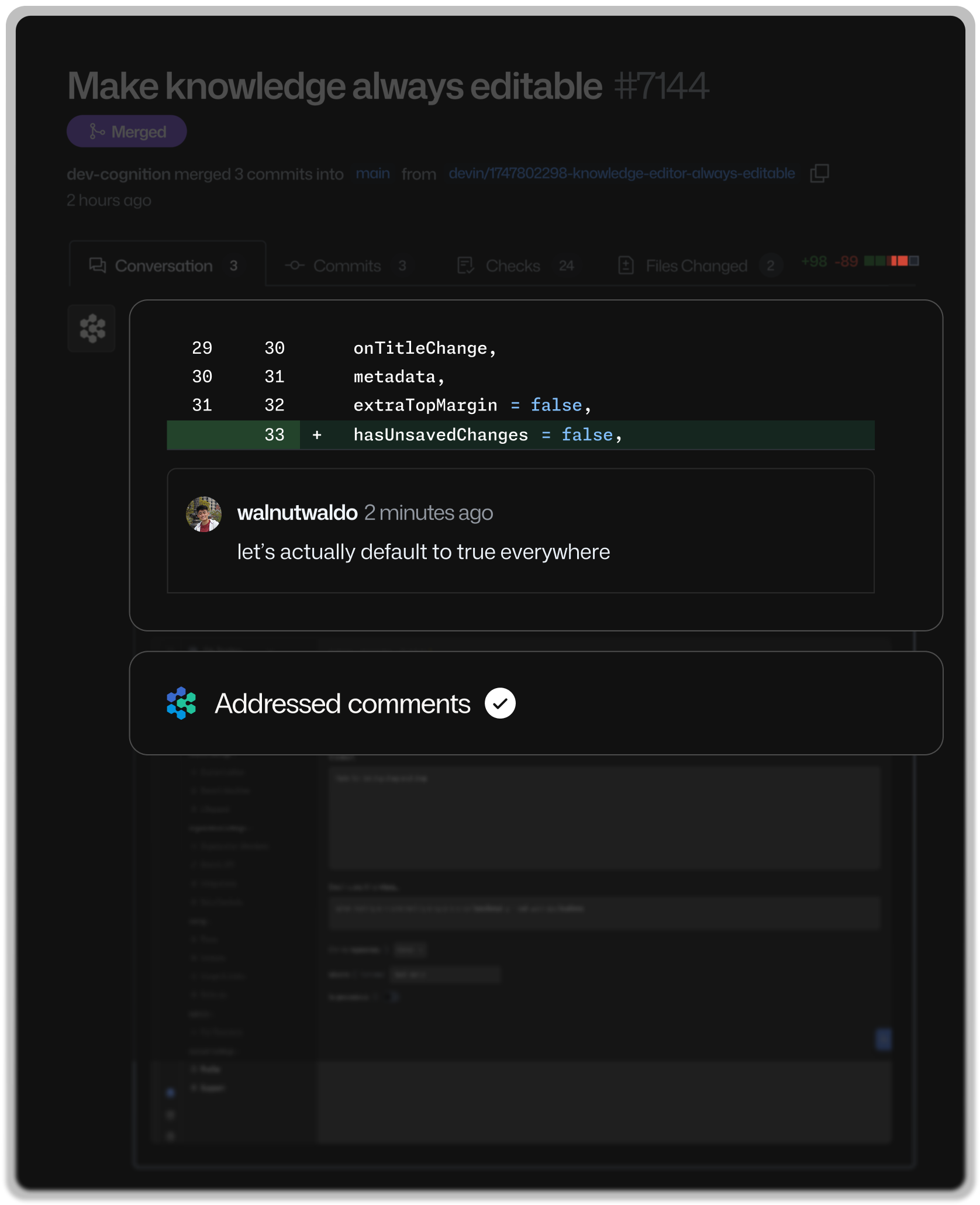
ドキュメンテーション 数十年分のコードが
数十年分のコードが
わずか数分で
ドキュメント化
レガシーコードベース向けの自動生成ドキュメントとシステム図 —
チームが構築していないシステムへの包括的な可視性を提供。
COBOL .NET C/C++ Assembly Fortran Perl Java その他
300k+ リポジトリをドキュメント化
3M+ COBOLコード行をドキュメント化
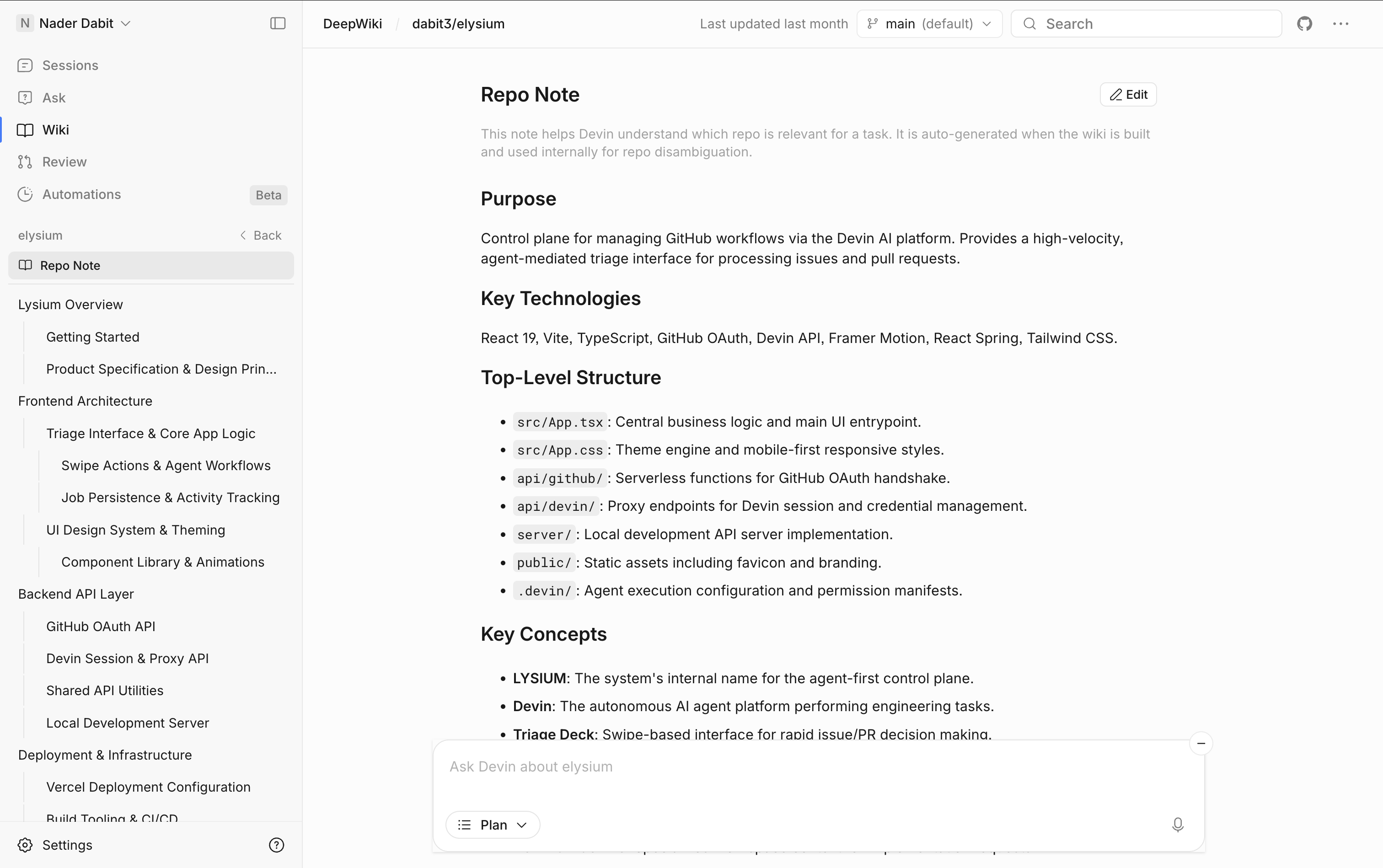
メンテナンス、品質、& セキュリティ システムを確実に、そして
システムを確実に、そして
安全な稼働を維持
コードベース全体にわたる自動コードレビュー、テスト生成、
インシデント対応。チームが次の課題に集中できるよう、
Devinがシステムの安定性を維持。
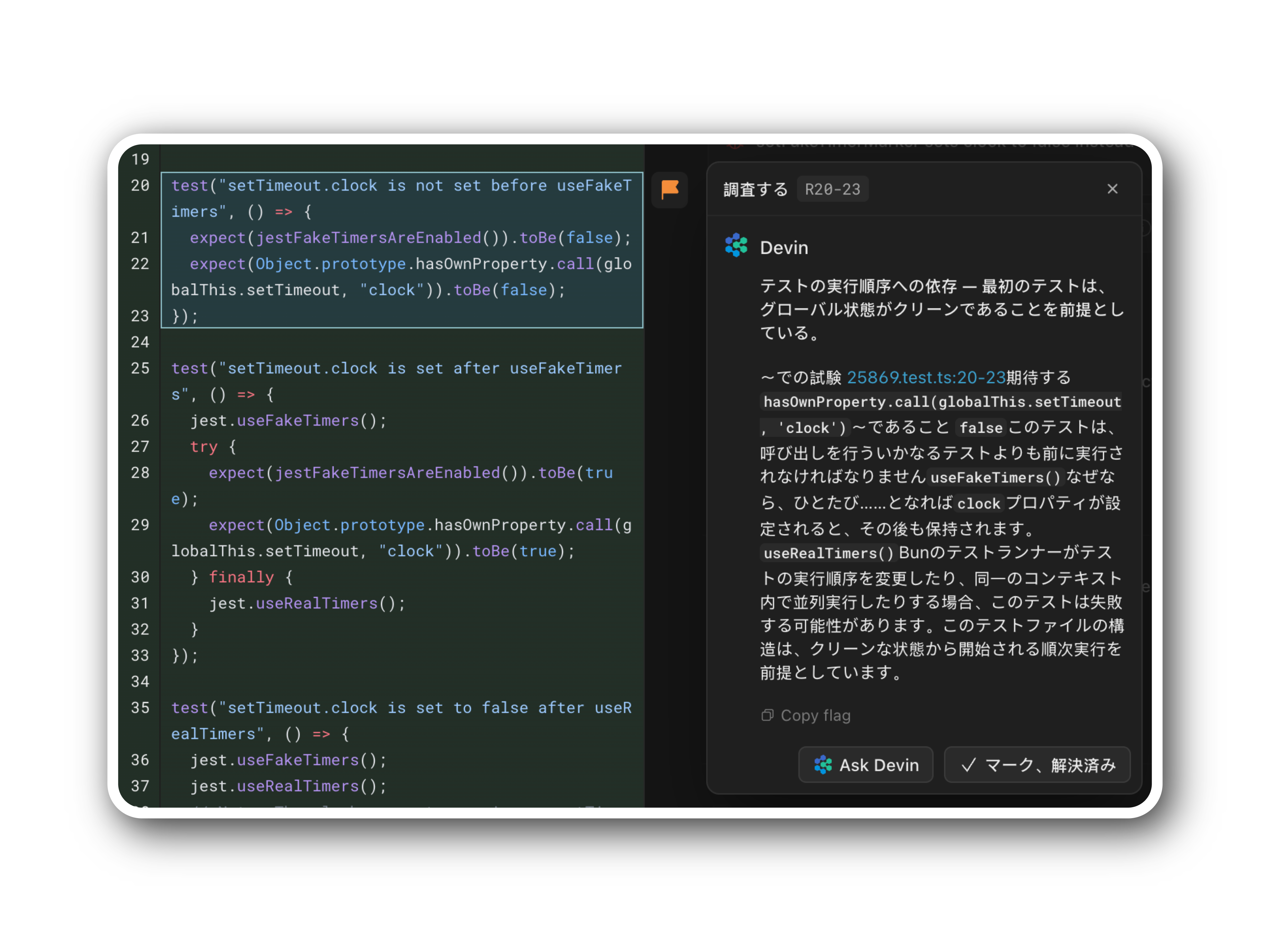
コードレビュー
Devinはバグ、リグレッション、品質問題を自動的に検出 — これにより少規模な
チームでも大規模エンジニアリング組織並みのカバレッジを実現。
テスト生成
コードベース全体にわたってユニットテスト、
インテグレーションテスト、
QAテストを自動生成。
インシデント対応
本番環境での問題に対する自動
トリアージ、根本原因分析、生成の修正。
70-90% のセキュリティ脆弱性を修復 世界トップ50に入る某銀行
8x ユニットテストのカバレッジ向上 世界トップ10に入る某保険会社