Cognition Team August 2025 5 minute read
Build your own AI data analyst (Part 2)
This post is the second in a two-part series on building AI data analysts with Devin and MCP. You can read more about why we turned Devin into our own AI data analyst and how we use it in Part 1.
In Part 2, we'll go over the details of how we built Devin into our own AI data analyst. Here's what we'll cover:
- A quick start guide to create an AI data analyst
- An example MCP configuration for a common database (PostgreSQL)
- Knowledge configuration examples to help your AI understand your data
- Troubleshooting help if you get stuck
Before you begin
Before we dive into specifics, it's worth mentioning that having a legible and structured data setup is strongly recommended for using Devin as an AI data analyst. It's impossible for anyone, let alone an AI, to understand your data if it's not structured in a way that's easy to parse and understand. In our case, we use DBT, which allows us to represent our infrastructure as code and version control our data models and pipelines.
Mapping your data
If you don't already represent your data models and pipelines as code, we suggest taking a few minutes to write down your general architecture, data flow, and what databases you're using before you get started.
This will allow you to:
- Understand your data better, including what MCPs you may need to install to access your data
- Provide Devin with the Knowledge it needs to be effective
Quick Start Guide
- Check out the MCP Marketplace and install the integrations for your particular databases and resources, or choose “Add Your Own” if what you need isn’t in our marketplace
- Configure your DB credentials
- Click “Use MCP” to start your first session. You can use our default prompt or ask for something relevant to your use case
- Add Knowledge that Devin should use when doing data analysis. Remember to attach a macro to the Knowledge (e.g. !analytics) so that you can conveniently invoke the Knowledge in your prompts
We've made it easy to connect Devin to your company's data. Devin is set up with Google's MCP Toolbox for Databases, and fully supports all major databases out of the box, including PostgreSQL, Firestore, Looker, and SQL Server. We're adding full support for the long tail of databases soon. In the meantime, you may need to add the appropriate credentials file to Devin's machine for a small number of databases (select “Modify repo setup” on any repo, and add the credentials file to the machine image).
Additionally, we built and open-sourced an MCP server for Metabase. You can find the code here. It has 80+ tools available for general database exploration as well as finding, creating, and answering questions about objects in Metabase including Dashboards, Cards, and Queries.
Below, we walk through a step-by-step example of how to configure a Supabase hosted PostgreSQL database.
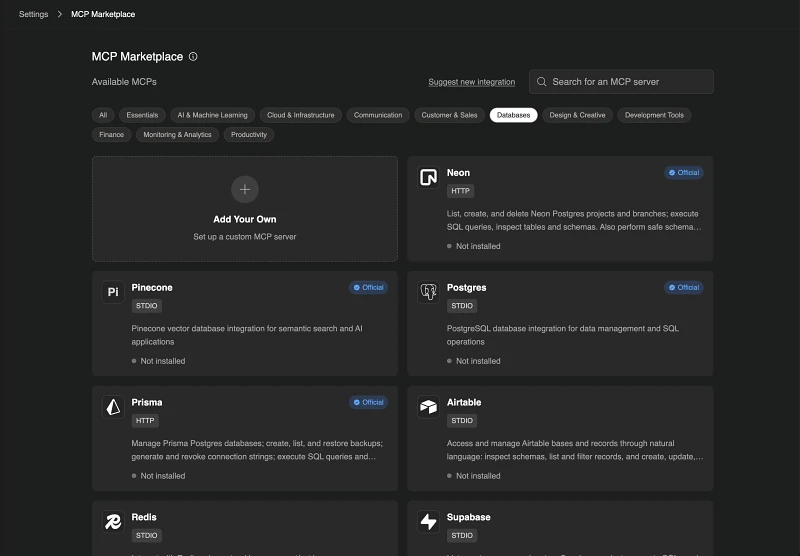
Step 1: Find the database relevant to you in the MCP Marketplace
- Navigate to Settings > MCP Marketplace
-
Click on the “Databases” pill to filter to just database MCPs
-
Click into the relevant database. In this example, we’ll set up the PostgreSQL MCP


Step 2: Find your database connection details
This step will differ based on your specific setup.
Note: We recommend limiting production database access to a read-only user credentials.
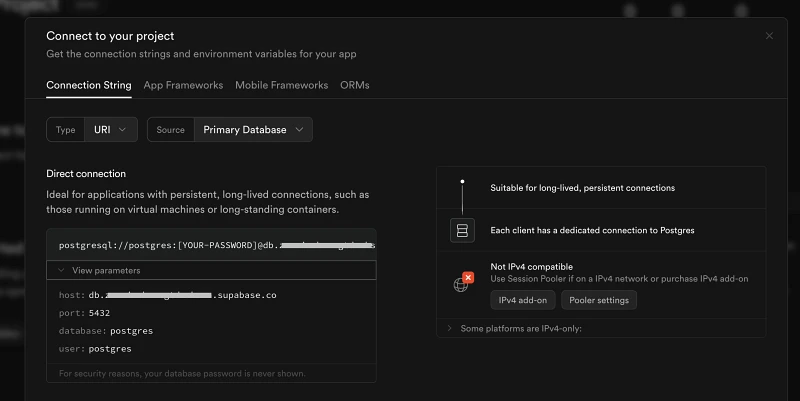
In our example we’re setting up a Supabase PostgreSQL database:
- Navigate to the relevant Supabase project
- Click “Connect” at the top of the screen
-
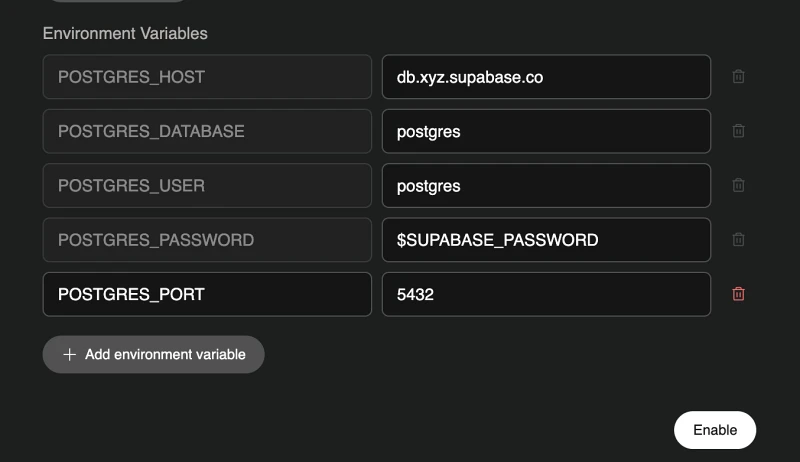
Copy the connection details. The ones you’ll need for PostgreSQL are:
- POSTGRES_HOST (e.g. db.xyz.supabase.co)
- POSTGRES_DATABASE (e.g. postgres)
- POSTGRES_USER (e.g. postgres)
- POSTGRES_PASSWORD
- POSTGRES_PORT (e.g. 5432)

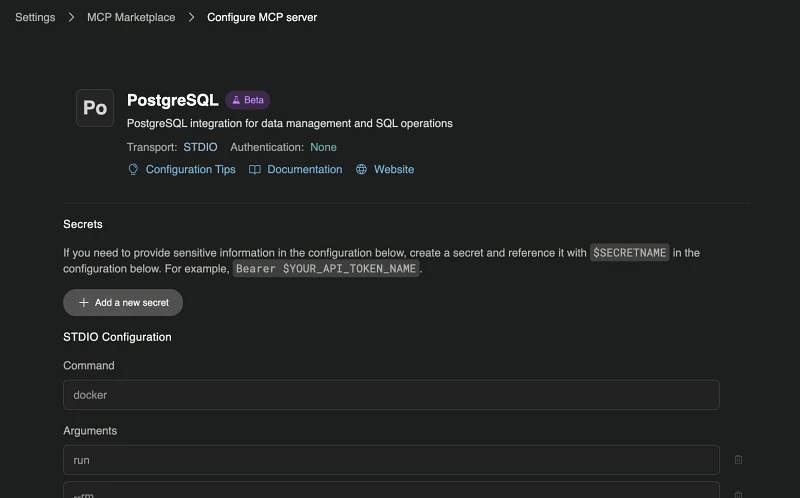
Step 3: Configure and enable the MCP
-
Fill in the relevant connection details in the MCP server page in Devin
- Click “Enable” at the bottom of the page

Step 4: Test the connection
-
Click “Test listing tools” to test that listing tools works successfully. If successful, the UI should show the list of available tools:
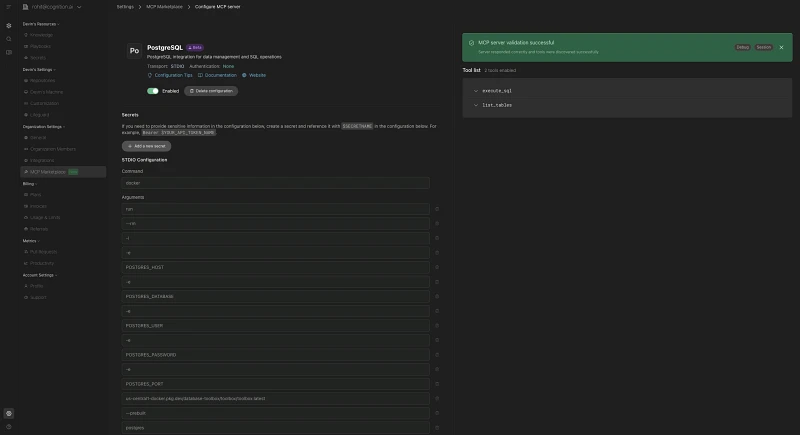
-
Click “Use MCP” to start your first session.


Common Errors & Tips:
- network is unreachable : Verify your host and port settings
- connection refused : Ensure that you’re using the correct pooler type and port
Once you’ve enabled the MCP, you can start using it right away. You can use our default prompt or ask for something relevant to your use case!
Knowledge configuration example & tips
While having your entire codebase in context is helpful, much relevant knowledge exists outside of code. It may reside in Notion, Confluence, or in the minds of your domain experts. Devin offers programmable Knowledge you can add to equip it with the context it needs for data analysis.
Add Knowledge in Settings > Knowledge. Tip: Attach a macro (e.g. !analytics) to Knowledge so your team can quickly invoke it by including the macro in any message (highly recommended). Devin will automatically receive the complete Knowledge contents when the macro is invoked.
The option to add a macro is at the very bottom of the Knowledge creation page:

Most data questions at Cognition begin by invoking the !analytics macro:

This Knowledge might simply direct Devin to relevant sources and documentation, outline your preferred best practices, or specify how to format results.
In our case, we point Devin to our analytics repo Readme.md file, which provides a comprehensive overview of our structure. We also instruct Devin to include a direct link to our visualization platform (Metabase) alongside any data insights. This allows users to immediately explore the underlying data, tweak SQL queries, and verify Devin’s work. We share an example below:
## Purpose: **Querying Redshift Data Warehouse:** When you need to answer data-related questions or obtain analytics by querying the Redshift data warehouse, you should use the `mcp-cli` tool. ## Guidelines when using this knowledge: - Get the complete db schema to see what tables and columns are available using the `database://structure` resource - Read the README.md docs in the analytics repo, specifically the section for key models and other useful models to learn what the most important tables on the analytics schema are. - Read all of the docs.yml files to learn about the analytics schema. - When in doubt, read the code in the analytics repo to learn how each column is calculated and where the data is coming from - Strongly prefer to use mart models (defined inside the mart folder, those that don't have an int_ or stg_ prefix) before int_ and stg_ models - Strongly prefer to query tables under the analytics schema, before querying any other schemas like the devin or billing schemas (raw tables) - If unsure, confirm with the user. Providing suggestions of tables to use - If required, you might do some data analysis using python instead of pure SQL. Connect to redshift using a python script and then use libraries like pandas, numpy, seaborn for visualization ## Output format - When running queries against redshift and providing the user with a final answer, always show the final query that produced the result along with the result itself, so that the user is able to validate the query makes sense. - Once you've reached a final query that you need to show to the user, use get_metabase_playground_link to generate a playground link where the user can run the query themselves. Format it as a link with the 'metabase playground link' label as the link text, using slack's markdown format. This is A MUST - Include charts or tables formatted as markdown if needed - If the final result is a single number, make sure to show this prominently to the user so it's very easy to see ### Identifying the right columns to use and how to filter data For categorical columns, you might want to select distinct values for a specific column to see what the possible options are and how to filter data Read the model definitions in the dbt folders to see how that column is computed and what possible values it might have
Tips:
- While not required, we recommend configuring SQL/dbt context via a repo. This tends to help Devin more quickly acquire the necessary context.
- Set Devin up to include links to a playground where users can quickly run Devin's queries themselves. This makes it much easier to validate and build on top of Devin's work. Within the next couple of days, we'll be adding a tool to the Metabase MCP which allows Devin to easily return links to the Metabase playground with a sql query pre-populated.
We'd love to help!
Stuck or have questions? Email us at support@cognition.ai with your Devin organization name and a link to this blog post.
support@cognition.ai