Cognition Team August 2025 6 minute read
Build Your Own AI Data Analyst (Part 1)
This post is the first in a two-part series on building AI data analysts with Devin and MCP. For a step-by-step guide, check out Part 2.
Introduction
Our #analytics Slack channel looks completely different than it did a year ago. Like most companies, we used to struggle with analytics. Even seemingly simple questions like "Why is enterprise plan revenue spiking for this cohort?" led to ping chains of doom.
I’m not the right person to ask, maybe try @Bob
Getting answers often took days or weeks. Now, it takes minutes. What changed? We trained our own 24/7 on-demand data scientist.
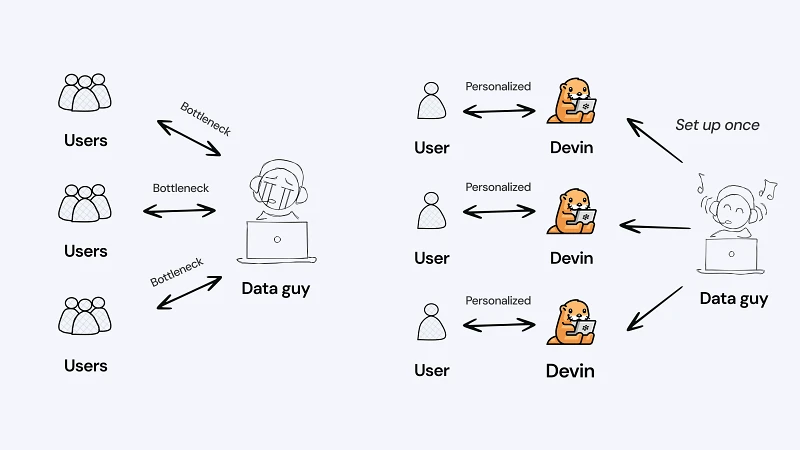
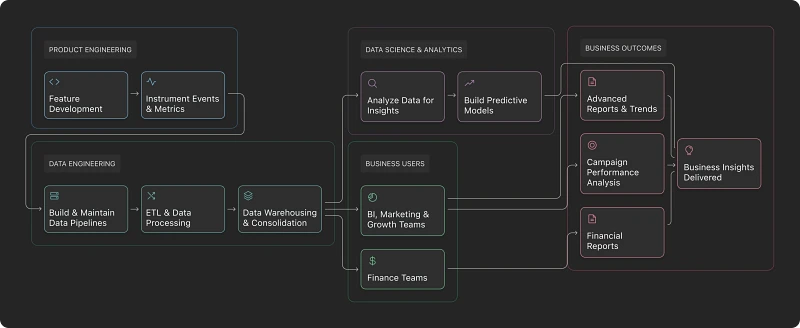
Previously, knowledge fragmentation made it extremely difficult to trace data anomalies back to their source or ask new questions. This fragmentation is common across organizations, with specialized knowledge scattered across different teams:
- Product Engineers develop feature X, and add instrumentation of events and metrics based on business logic.
- Data Engineers manage complex data pipelines and ETL processes to make data available in data warehouses, applying post-processing logic and consolidating data into more easily digestible views
- Data Scientists and Analysts consume this data to gain insights and build predictive models
- BI / Marketing / Growth team members consume this data to build advanced reports, view trends, measure campaign performance, etc.
-
Finance departments crunch numbers on cost, revenue, margin reports, etc.

We solved this issue by training our own AI data analyst by connecting Devin, our AI software engineer, to MCPs for our databases and resources. This way, knowledge fragmentation is no longer an issue, since the data team can train one AI data analyst and set it up for the rest of the team to use. Our team can now answer questions faster, allowing the data team to focus on more complex questions and projects.
Why Train Your AI Software Engineer as a Data Scientist?
Devin is an AI software engineer. This means that Devin can understand both our codebase and our data. Devin:
- Excels at codebase understanding (try it at deepwiki.com!)
- Can search through all of our product code, instrumented events, ETL pipelines, and the final transformations and data models
- Can pick up Knowledge about our company and products from past sessions
While other SQL‑focused tools only see final results materialized in our tables, context on how each column is actually computed is key when doing data analysis end‑to‑end.
Let’s say a product manager wants insights into feature adoption. They might not actually know the internals of the data schema, what events are available, where numbers come from, and which tables and columns to use. Devin, on the other hand, can rapidly search your entire codebase to find the best matches to answer the question, and can also verify what it found by running SQL queries over your data.
Data Intelligence Is an Async Collaborative Task
A non‑trivial data analytics question often involves back‑and‑forth querying and exploration: initial queries lead to follow-ups, validating insights with additional queries, creating time series plots or comparing across cohorts, etc.
Devin excels at supporting these long-running, iterative workflows: kick off analysis from Slack, get notified when results are ready, and seamlessly pull in teammates for verification or discussion when needed.
Here’s what our analytics channel typically looks like:

Technical Overview: MCP + Databases
MCP (Model Context Protocol) is an open protocol that enables AI agents like Devin to securely communicate with external tools and services. Think of it as a toolbox you can give to your AI agent to do its job.
MCP servers abstract away complexity by providing tools directly to agents, eliminating the need to manage intermediate steps. This means neither users nor agents need to set up direct connections or navigate complex infrastructure. Agents can focus on their primary tasks without getting lost in technical details, as the MCP handles securing connections, tool execution, and results processing behind the scenes. MCP servers give Devin superpowers!
We recently shipped the MCP Marketplace, making it easy to install and use dozens of high-quality MCP integrations for various tools and services. You can also install MCPs that are not in our marketplace yet using the "Add Your Own" option.

In the context of data analytics, MCP acts as a bridge between Devin and our company's databases and external services. At its core, MCP provides a standardized way for AI agents to use tools and access resources:
- Access databases securely: Connect to our data warehouse without exposing credentials directly to the agent
- Explore schemas: Understand table structures, relationships, and data types
- Execute queries: Run SQL against our database or data warehouse with proper permissions
- Process results: Format and visualize query outputs in an agent-optimized way
- Share easily verifiable results: Include links to dashboards, visualizations and interactive results which you can easily edit and verify
This flow can be visualized in the following diagram:

What makes this model so powerful is that all we need to do is connect Devin to MCPs for our databases and resources. And because we can leverage Devin's brainpower, we can often trust that Devin will figure out what tools to use and how to use them. We don't need to define workflows for Devin to use.
In a real-world scenario, Devin might do several exploratory SQL queries before a conclusion is reached and finally shared with the user. We will explore some examples below.
Real-World Analytics Workflows
Let's say we just launched a new feature and want to understand its impact on users. We can ask Devin to help us analyze the data.

Notice that there’s no need to specify details like where to pull the data from. Devin already knows the codebase and can find what it needs. After a few minutes, Devin responds on Slack:

Devin can also help us visualize the Neon user engagement data alongside reliability metrics pulled from Sentry.

Importantly, we can quickly verify Devin’s work. Devin provides the final query for us to audit, build on top of, and run in Neon ourselves to verify.

This type of work is now repeated dozens of times every day across our company. If you assume that every question would take an hour to answer, we estimate that it would take a data team 150+ hours per month to do this work manually. With Devin, we can do it in minutes.
Beyond Basic Queries
Devin can also go beyond basic queries and help you with more complex tasks. Here are some examples from our company and other enterprises:
Data warehouse exploration
Devin can map your database structure, navigate complex schemas and help you identify the right data sources for your analysis
Implementing schema changes
After some exploratory data analysis, you can ask Devin to implement structural improvements to your data organization.
Find Data Gap
This helps identify potential data gaps or inconsistencies before they can negatively impact your business decisions.
Data segmentation
Understand what the biggest contributors and groups are for your particular use case. Devin can slice data in meaningful ways to reveal hidden patterns and opportunities.
Understanding Feature Adoption
Devin can analyze usage patterns to identify which features are most valuable to your users and which might need improvement or promotion.
Forecasting
Devin can apply time-series forecasting techniques to your historical data, helping you predict future metrics and make data-driven strategic decisions.
Getting Started
For instructions and tips on how to create an AI data analyst for your team:
Check out Part 2